Benchmarking Clustering Algorithms for Stem Cell Subpopulation Identification: A Practical Guide for Single-Cell Data Analysis
The accurate identification of stem cell subpopulations is crucial for advancing regenerative medicine, understanding disease mechanisms, and developing targeted therapies.
Benchmarking Clustering Algorithms for Stem Cell Subpopulation Identification: A Practical Guide for Single-Cell Data Analysis
Abstract
The accurate identification of stem cell subpopulations is crucial for advancing regenerative medicine, understanding disease mechanisms, and developing targeted therapies. This article provides a comprehensive benchmark of computational clustering algorithms for stem cell research, evaluating their performance on single-cell transcriptomic and proteomic data. We explore foundational concepts of stem cell heterogeneity and the critical role of clustering in delineating distinct cellular states. Based on recent large-scale benchmarking studies, we recommend top-performing algorithms like scAIDE, scDCC, and FlowSOM for their balanced performance across metrics. The article addresses common analytical challenges including parameter optimization, handling high-dimensional data, and integration of multi-omics information. Finally, we discuss validation strategies and future directions where artificial intelligence and systems biology are poised to transform stem cell analysis and clinical translation.
Understanding Stem Cell Heterogeneity and the Critical Role of Clustering in Single-Cell Analysis
Stem cell heterogeneity represents a fundamental biological characteristic with profound implications for both developmental biology and regenerative medicine. This phenomenon refers to the existence of distinct subpopulations within a stem cell pool, each possessing unique functional capacities, differentiation potentials, and molecular signatures. Far from being a uniform population, stem cells comprise a consortium of different cell types with distinct steady-state characteristics, including variations in self-renewal capacity, proliferation rates, differentiation bias, and lifespan [1]. This heterogeneity is not merely biological noise but serves critical functions in development, tissue maintenance, and response to injury or disease.
The recognition of stem cell heterogeneity has evolved significantly over time. Initially, stem cells were perceived as a homogeneous population with flexible behavior, but advanced single-cell technologies have revealed a more complex landscape [2]. For example, in the hematopoietic system, once thought to be sustained by a single type of flexible stem cell, we now know the compartment consists of a limited number of discrete stem cell subsets with epigenetically fixed differentiation and self-renewal programs [2]. This paradigm shift has forced a reevaluation of stem cell biology across tissues and has important consequences for therapeutic applications.
Understanding stem cell heterogeneity is particularly crucial for advancing cell-based therapies and regenerative medicine applications. The inherent variability in stem cell populations contributes significantly to the inconsistent outcomes observed in clinical trials [3] [4]. For mesenchymal stem cells (MSCs), heterogeneity manifests through multiple dimensions, including uncertainty in nomenclature, differences between donors, variations across tissue sources, and intercellular differences even within clonally derived populations [3]. Addressing these challenges requires sophisticated computational and experimental approaches to dissect and characterize the diverse subpopulations that constitute the stem cell compartment.
Computational Benchmarking of Clustering Algorithms
The Critical Role of Clustering in Heterogeneity Analysis
Single-cell RNA-sequencing (scRNA-seq) has revolutionized our ability to profile gene expression at individual cell resolution, enabling the precise characterization of stem cell heterogeneity [5] [6]. Clustering algorithms serve as fundamental computational tools in this process, allowing researchers to identify distinct cell subpopulations and estimate the number of unique cell types present in a given dataset [6]. The performance of these algorithms directly impacts the accuracy of stem cell subpopulation identification and consequently affects downstream biological interpretations.
The challenge of clustering single-cell data is compounded by the unique characteristics of different omics modalities. Single-cell proteomic data, for instance, often exhibits markedly different data distributions and feature dimensionalities compared to transcriptomic data, posing non-trivial challenges for applying clustering techniques uniformly across modalities [5]. As the field progresses toward multi-omics approaches, understanding the strengths and limitations of clustering algorithms across different data types becomes increasingly important.
Comprehensive Performance Evaluation
A recent systematic benchmark evaluation assessed 28 computational clustering algorithms on 10 paired transcriptomic and proteomic datasets, providing critical insights into their performance for stem cell heterogeneity research [5]. The study evaluated methods across multiple criteria, including clustering accuracy, robustness, running time, and peak memory usage. The results revealed that while numerous clustering algorithms have been developed for single-cell transcriptomic data, relatively few methods have been specifically tailored for single-cell proteomic data.
Table 1: Top-Performing Clustering Algorithms Across Omics Modalities
| Algorithm | Transcriptomic Performance (Rank) | Proteomic Performance (Rank) | Computational Efficiency | Key Strengths |
|---|---|---|---|---|
| scAIDE | 2nd | 1st | Moderate | Excellent cross-modality performance |
| scDCC | 1st | 2nd | High memory efficiency | Strong generalization across omics |
| FlowSOM | 3rd | 3rd | High robustness | Fast processing with consistent results |
| CarDEC | 4th | 16th | Variable | Transcriptomic-specific optimization |
| PARC | 5th | 18th | Variable | Limited proteomic performance |
The benchmarking results demonstrated that scAIDE, scDCC, and FlowSOM consistently achieved top performance across both transcriptomic and proteomic data types, suggesting strong generalization capabilities [5]. This cross-modality consistency is particularly valuable for stem cell researchers working with diverse data types. Importantly, the study revealed that algorithms performing well on one modality did not necessarily maintain their performance on another, highlighting the importance of selecting appropriate methods based on specific data characteristics.
Algorithm Performance Across Experimental Conditions
Further benchmarking examined how clustering algorithms perform under varying biological conditions relevant to stem cell research. A separate comprehensive evaluation focused on algorithm performance in estimating the number of cell types across datasets with different characteristics, including varying numbers of cell types, different cell counts per type, and imbalanced cell type proportions [6]. These conditions mirror the challenges faced when analyzing stem cell populations, where subpopulations may exist at different abundances and possess distinct transcriptional profiles.
Table 2: Algorithm Performance for Cell Type Number Estimation
| Algorithm | Estimation Bias | Performance with Imbalanced Populations | Stability Across Datasets | Recommended Use Cases |
|---|---|---|---|---|
| Monocle3 | Low deviation | Moderate | High | General purpose estimation |
| scLCA | Low deviation | Moderate | Moderate | Balanced population designs |
| scCCESS-SIMLR | Low deviation | Good | High | Complex population structures |
| SHARP | Underestimation | Poor | Moderate | Computational efficiency priority |
| SC3 | Overestimation | Moderate | Low | Exploration of potential subtypes |
| ACTIONet | Overestimation | Poor | Low | Large dataset exploration |
The findings revealed that methods exhibited different bias patterns, with some consistently overestimating (e.g., SC3, ACTIONet, Seurat) or underestimating (e.g., SHARP, densityCut) the number of cell types [6]. These biases can significantly impact stem cell research, potentially leading to either oversplitting of continuous differentiation trajectories or missing rare stem cell subpopulations. Methods such as Monocle3, scLCA, and scCCESS-SIMLR demonstrated more balanced performance with smaller median deviations from the true number of cell types [6].
Experimental Methodologies for Resolving Heterogeneity
Single-Cell RNA Sequencing Workflows
The characterization of stem cell heterogeneity relies heavily on robust experimental methodologies that enable resolution at the single-cell level. Single-cell RNA sequencing (scRNA-seq) has emerged as a cornerstone technology for profiling the transcriptomic landscape of individual cells within heterogeneous stem cell populations [6]. A typical scRNA-seq workflow begins with the preparation of a single-cell suspension from stem cell cultures or primary tissues, followed by cell capture, reverse transcription, cDNA amplification, library preparation, and high-throughput sequencing.
The critical importance of proper experimental design cannot be overstated when studying stem cell heterogeneity. Factors such as cell viability, capture efficiency, sequencing depth, and batch effects can significantly impact the ability to resolve biologically meaningful subpopulations. For stem cells specifically, considerations about cell cycle status, differentiation stage, and metabolic state must be incorporated into experimental planning, as these factors contribute substantially to observed heterogeneity [7] [1]. Following data generation, quality control metrics including reads per cell, percentage of mitochondrial genes, and detection of housekeeping genes should be rigorously assessed to ensure data reliability.
Surface Protein Profiling with CITE-seq
While scRNA-seq provides comprehensive transcriptomic information, the addition of surface protein profiling through technologies such as CITE-seq (Cellular Indexing of Transcriptomes and Epitopes by Sequencing) enables simultaneous measurement of mRNA and protein expression in individual cells [5]. This multi-modal approach is particularly valuable for stem cell research, as protein expression often more closely reflects functional cellular states than transcript levels alone.
The CITE-seq methodology involves labeling cells with oligonucleotide-tagged antibodies against specific surface markers, followed by simultaneous capture of transcriptomic and proteomic information using standard single-cell sequencing platforms [5]. For stem cell applications, panels of antibodies targeting known stem cell markers (e.g., CD90, CD73, CD105 for MSCs) can be combined with antibodies against differentiation markers to resolve heterogeneity along developmental trajectories. The resulting multi-modal data provides complementary information that enhances the identification of functionally distinct subpopulations within heterogeneous stem cell cultures.
Functional Validation Approaches
Following computational identification of putative stem cell subpopulations, functional validation remains essential to establish biological significance. In vitro differentiation assays represent a cornerstone approach for validating functional heterogeneity within stem cell populations. The standard trilineage differentiation assay for MSCs, as defined by International Society for Cell & Gene Therapy (ISCT) criteria, evaluates adipogenic, osteogenic, and chondrogenic differentiation potential [3] [8] [4].
Clonal tracking methods provide another powerful approach for validating stem cell heterogeneity. Through genetic barcoding or lineage tracing, researchers can directly monitor the differentiation potential and self-renewal capacity of individual stem cells over time [2] [1]. These studies have been instrumental in demonstrating the existence of preprogrammed hematopoietic stem cell subsets with distinct differentiation biases [2]. Similarly, in vivo transplantation assays remain the gold standard for assessing functional stem cell activity, particularly for hematopoietic stem cells, where reconstitution capacity can be quantitatively measured in recipient models [2].
Research Reagent Solutions for Heterogeneity Studies
The experimental and computational approaches for analyzing stem cell heterogeneity depend on a suite of specialized reagents and tools. The following table outlines essential research reagent solutions for designing robust studies of stem cell heterogeneity.
Table 3: Essential Research Reagents for Stem Cell Heterogeneity Studies
| Reagent Category | Specific Examples | Function in Heterogeneity Studies | Application Notes |
|---|---|---|---|
| Surface Marker Antibodies | CD105, CD73, CD90, CD45, CD34, CD14 | Identification and isolation of stem cell populations using ISCT criteria [3] [8] | Essential for flow cytometry and CITE-seq experiments; validate specificity for each species |
| Oligonucleotide-Tagged Antibodies | CITE-seq antibodies | Simultaneous protein and RNA measurement at single-cell level [5] | Enables multi-omics approaches; requires compatibility with sequencing platform |
| Cell Culture Supplements | FGF, EGF, TGF-β inhibitors | Maintenance of stemness or directed differentiation [7] [2] | Different stem cell subpopulations may have distinct growth factor requirements |
| Cell Separation Matrices | Ficoll, Percoll, BSA gradients | Enrichment of specific subpopulations based on density [4] | Can reduce cellular stress compared to fluorescence-activated cell sorting |
| Single-Cell Library Preparation Kits | 10x Genomics, Parse Biosciences | Generation of barcoded libraries for single-cell sequencing [5] [6] | Choice affects cell throughput, sequencing depth, and cost considerations |
| Lineage Tracing Systems | Genetic barcodes, Cre-lox, Fluorescent reporters | Tracking clonal dynamics and differentiation trajectories [2] [1] | Critical for functional validation of computationally identified subpopulations |
The selection of appropriate reagents should be guided by the specific stem cell type under investigation and the particular aspects of heterogeneity being studied. For example, the study of age-related heterogeneity in hematopoietic stem cells requires different marker panels (e.g., CD41, CD150) than the analysis of mesenchymal stem cell subpopulations [2] [1]. Similarly, the investigation of pluripotent stem cell heterogeneity necessitates reagents specific to pluripotency markers (e.g., OCT4, NANOG, SOX2) and early lineage commitment [7].
Biological Implications of Stem Cell Heterogeneity
Developmental Regulation and Fate Decisions
Stem cell heterogeneity is not merely biological noise but serves crucial functions in development and tissue homeostasis. Emerging evidence indicates that multiple aspects of cellular physiology, including epigenetic regulation, transcriptional networks, mitotic behavior, signal transduction, and metabolic pathways, differ among heterogeneous stem cells [1]. These differences enable stem cell populations to participate in multilineage differentiation throughout life and maintain homeostasis or remodel tissues in response to physiological changes.
In the hematopoietic system, heterogeneity is developmentally regulated, with different stem cell subsets dominating at various life stages [2]. Lymphoid-biased HSCs are found predominantly early in life, while myeloid-biased HSCs accumulate in aged organisms, contributing to age-related changes in immune function [2] [1]. This programmed heterogeneity has profound implications for understanding developmental biology and age-related diseases. Similarly, in mesenchymal stem cells, heterogeneity reflects developmental origins, with cells from different tissue sources (bone marrow, adipose tissue, umbilical cord) exhibiting distinct gene expression profiles and functional properties [3] [4].
Implications for Regenerative Medicine
The inherent heterogeneity of stem cell populations presents both challenges and opportunities for regenerative medicine applications. On one hand, heterogeneity contributes to inconsistent outcomes in clinical trials of MSC-based therapies, making it difficult to predict and replicate therapeutic effects [3] [8] [4]. Different MSC subpopulations may exhibit varying potencies for specific therapeutic applications, such as immunomodulation, tissue repair, or angiogenesis.
On the other hand, understanding and harnessing heterogeneity could lead to more targeted and effective therapies. For example, the identification of specific subpopulations with enhanced immunomodulatory capacity or trophic factor secretion could enable purification of cells optimized for particular clinical indications [4]. Strategies to address heterogeneity challenges in clinical applications include donor cell pooling to reduce inter-donor variability, functional pre-screening of cell batches, and development of more precise characterization methods that go beyond surface marker expression to include functional potency assays [8] [4].
The challenge of stem cell heterogeneity represents both a fundamental biological phenomenon and a significant technical hurdle in the field of regenerative medicine. Through the integration of advanced computational approaches, particularly sophisticated clustering algorithms like scAIDE, scDCC, and FlowSOM, with multi-omics experimental methodologies, researchers are making steady progress in resolving the complexity of stem cell populations. The benchmarking studies summarized in this review provide critical guidance for selecting appropriate analytical tools based on specific data modalities and research questions.
As our understanding of stem cell heterogeneity deepens, it becomes increasingly clear that this diversity is not merely biological noise but rather a functionally important feature of stem cell populations. The regulated heterogeneity enables flexible responses to developmental cues, tissue damage, and aging processes. For clinical translation, addressing heterogeneity through improved characterization, standardization, and potentially subpopulation selection will be essential for developing more consistent and effective stem cell-based therapies. The continued refinement of both computational and experimental approaches for dissecting stem cell heterogeneity will undoubtedly yield new insights into basic biology and accelerate the development of regenerative medicine applications.
In the rapidly evolving field of regenerative medicine, accurately identifying and characterizing cellular subpopulations stands as a fundamental prerequisite for developing effective therapies. Single-cell RNA sequencing (scRNA-seq) has revolutionized our ability to profile gene expression in individual cells, enabling researchers to dissect cellular heterogeneity within complex tissues. Clustering algorithms serve as the computational backbone for this process, transforming high-dimensional transcriptomic data into biologically meaningful cell type classifications. The critical importance of this step cannot be overstated—the precise definition of cellular identity directly influences downstream applications, including stem cell differentiation protocols, disease modeling, and the identification of novel therapeutic targets.
Despite technological advancements, clustering remains a challenging endeavor due to the inherent complexity and high dimensionality of single-cell data. The performance of clustering algorithms varies significantly across different biological contexts, data types, and computational parameters. Recent comprehensive benchmarking studies have revealed that no single algorithm consistently outperforms others across all scenarios, highlighting the need for careful method selection tailored to specific research goals in regenerative medicine [5]. This guide provides an objective comparison of clustering performance, experimental protocols, and practical implementation guidelines to empower researchers in making informed decisions for their stem cell research.
Benchmarking Clustering Performance: A Quantitative Comparison
Comprehensive Algorithm Performance Assessment
A systematic benchmark evaluation of 28 computational clustering algorithms was conducted on 10 paired transcriptomic and proteomic datasets, providing robust performance comparisons across multiple metrics. The evaluation employed standardized measures including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Clustering Accuracy (CA), and Purity to ensure comprehensive assessment [5]. The table below summarizes the top-performing algorithms based on their overall rankings:
Table 1: Top-Performing Clustering Algorithms Across Single-Cell Omics Data
| Algorithm | Overall Ranking (Transcriptomics) | Overall Ranking (Proteomics) | Key Strengths | Computational Profile |
|---|---|---|---|---|
| scAIDE | 2nd | 1st | Superior performance across omics, excellent for heterogeneous populations | Balanced efficiency |
| scDCC | 1st | 2nd | Top transcriptomic performance, memory-efficient | Memory efficient |
| FlowSOM | 3rd | 3rd | Excellent robustness, maintains performance across data types | Time efficient |
| CarDEC | 4th | 16th | Strong transcriptomic performance | Variable performance |
| PARC | 5th | 18th | Effective for specific transcriptomic applications | Context-dependent |
The benchmarking analysis revealed that scAIDE, scDCC, and FlowSOM demonstrated consistent top-tier performance across both transcriptomic and proteomic data, suggesting strong generalization capabilities across different omics modalities [5]. Interestingly, some methods that performed exceptionally well on transcriptomic data (e.g., CarDEC and PARC) showed significantly reduced effectiveness on proteomic data, highlighting the modality-specific strengths of certain algorithms.
Performance Across Computational Metrics
Beyond overall accuracy, the benchmarking study evaluated critical computational resources including peak memory usage and running time, providing practical insights for researchers working with large-scale datasets:
Table 2: Computational Efficiency of Leading Clustering Algorithms
| Algorithm | Memory Efficiency | Time Efficiency | Recommended Use Case |
|---|---|---|---|
| scDCC | Excellent | Moderate | Large datasets with limited RAM |
| scDeepCluster | Excellent | Moderate | Memory-constrained environments |
| TSCAN | Moderate | Excellent | Rapid prototyping |
| SHARP | Moderate | Excellent | Time-sensitive projects |
| MarkovHC | Moderate | Excellent | Quick iterative analyses |
| Leiden | Good | Good | Balanced workflows |
| Louvain | Good | Good | General-purpose applications |
For researchers prioritizing computational efficiency, scDCC and scDeepCluster offer excellent memory efficiency, while TSCAN, SHARP, and MarkovHC provide superior time efficiency [5]. Community detection-based methods like Leiden and Louvain strike a reasonable balance between both dimensions, making them suitable for general-purpose applications in regenerative medicine research.
Experimental Protocols and Methodologies
Standardized Benchmarking Framework
The comparative benchmarking study employed a rigorous methodology to ensure fair and informative algorithm evaluation. The experimental protocol encompassed several critical phases:
Dataset Curation and Preparation: Ten real datasets across five tissue types encompassing over 50 cell types and more than 300,000 cells were obtained from SPDB (the largest single-cell proteomic database) and Seurat v3 [5]. These datasets included paired single-cell mRNA expression and surface protein expression data generated using multi-omics technologies (CITE-seq, ECCITE-seq, and Abseq), ensuring identical biological conditions across omics modalities for comparable analysis.
Algorithm Selection and Configuration: The study evaluated 28 clustering algorithms representing diverse computational approaches: 15 classical machine learning-based methods, 6 community detection-based methods, and 7 deep learning-based methods [5]. Most methods were developed after 2020, representing current state-of-the-art approaches. Each algorithm was applied according to its recommended settings with standardized preprocessing to ensure comparability.
Evaluation Metrics and Validation: Multiple validation metrics were employed including ARI, NMI, CA, and Purity. The robustness assessment utilized 30 simulated datasets with varying noise levels and dataset sizes to evaluate method stability under different conditions [5]. Additionally, the impact of highly variable genes (HVGs) and cell type granularity on clustering performance was systematically investigated.
Parameter Optimization Framework
A specialized study focused on clustering parameter optimization utilized intrinsic goodness metrics to predict clustering accuracy across different parameter configurations. The experimental approach included:
Dataset Selection: Three datasets with ground truth cell annotations from distinct anatomical districts (liver, skeletal muscle, and kidney) were selected from the CellTypist organ atlas to ensure biologically reliable labels independent of annotation algorithms [9].
Clustering Methods and Parameters: The investigation employed two clustering methods: the Leiden algorithm and the Deep Embedding for Single-cell Clustering (DESC) algorithm [9]. Parameters including resolution, number of nearest neighbors, dimensionality reduction approach, and number of principal components were systematically varied.
Linear Modeling and Metric Evaluation: A robust linear mixed regression model analyzed the impact of clustering parameters on accuracy [9]. Fifteen intrinsic measures were calculated and used to train an ElasticNet regression model in both intra- and cross-dataset approaches to evaluate accuracy prediction potential.
The workflow for this parameter analysis is illustrated below:
Enhanced Consensus Clustering for Single-Cell Methylation Data
For single-cell DNA methylation data, the scMelody algorithm employs an enhanced consensus-based clustering model that addresses limitations of single-similarity measures:
Similarity Reconstruction: scMelody utilizes multiple basic similarity measures to reconstruct cell-to-cell methylation similarity patterns, capturing more complete cellular heterogeneity than single-metric approaches [10].
Dual Weighting Strategy: The method incorporates a regularization process and dual weighting strategy that balances both diversity and separability of basic clustering partitions, improving consensus matrix construction [10].
Validation Framework: The algorithm was assessed on seven distinct real single-cell methylation datasets with known cell types, plus synthetic datasets with varying cell numbers, cluster numbers, and CpG dropout proportions to evaluate robustness [10].
The enhanced consensus approach demonstrates how integrating multiple similarity measures can overcome limitations of individual metrics:
Essential Research Reagent Solutions
Implementing effective clustering workflows requires both computational tools and wet-lab reagents that ensure high-quality input data. The following table details key solutions for single-cell research in regenerative medicine:
Table 3: Essential Research Reagent Solutions for Single-Cell Clustering Studies
| Reagent/Resource | Function | Application in Regenerative Medicine |
|---|---|---|
| CellTypist Organ Atlas | Provides meticulously curated cell annotations with ground truth labels | Benchmarking clustering performance against reliable biological standards [9] |
| CITE-seq Reagents | Simultaneous measurement of mRNA and surface protein expression | Paired transcriptomic and proteomic data generation for multi-modal clustering [5] |
| scBS/scRRBS/scWGBS Kits | Single-cell DNA methylation sequencing | Epigenetic heterogeneity analysis in stem cell populations [10] |
| SPDB Database | Largest single-cell proteomic database | Access to diverse proteomic datasets for method validation [5] |
| Highly Variable Gene Selection Tools | Identification of informative features for clustering | Improved clustering efficiency and biological relevance [5] |
Key Findings and Practical Recommendations
Optimal Parameter Configuration
The parameter optimization study yielded several critical insights for practical implementation. The analysis demonstrated that using UMAP for neighborhood graph generation combined with increased resolution parameters has a beneficial impact on accuracy [9]. The effect of resolution is particularly pronounced with fewer nearest neighbors, resulting in sparser, more locally sensitive graphs that better preserve fine-grained cellular relationships. Additionally, testing different numbers of principal components is essential as this parameter is highly affected by data complexity.
The study identified that within-cluster dispersion and the Banfield-Raftery index serve as effective intrinsic proxies for accuracy, enabling rapid comparison of different parameter configurations without requiring ground truth labels [9]. This approach facilitates more biologically plausible clustering outcomes in scenarios where cell type information is incomplete or unknown.
Algorithm Selection Guidelines
Based on the comprehensive benchmarking results, the following recommendations emerge for regenerative medicine applications:
- For top overall performance across both transcriptomic and proteomic data, prioritize scAIDE, scDCC, or FlowSOM [5]
- For memory-constrained environments, select scDCC or scDeepCluster due to their excellent memory efficiency [5]
- For time-sensitive projects, choose TSCAN, SHARP, or MarkovHC for their exceptional time efficiency [5]
- For single-cell methylation data, consider scMelody for its enhanced consensus approach and robust performance across diverse datasets [10]
- For general-purpose applications with balanced requirements, community detection-based methods (Leiden, Louvain) offer reliable performance [5]
Implications for Regenerative Medicine
The advancements in clustering methodologies have profound implications for regenerative medicine. AI-powered clustering can accelerate therapy development by analyzing complex molecular patterns in stem cell populations, identifying novel subpopulations, and predicting differentiation outcomes [11]. As single-cell technologies continue to evolve, incorporating multi-omic data integration and leveraging intrinsic validation metrics will be crucial for unlocking deeper insights into cellular identity and function in regenerative processes.
Single-cell technologies have fundamentally transformed stem cell research by enabling the examination of the fundamental units comprising biological organs, tissues, and cells [12]. These technologies have emerged as powerful tools with profound impact, opening new pathways for acquiring cell-specific data and gaining insights into the molecular pathways governing organ function and biology [12]. Traditional bulk omics approaches average signals from heterogeneous cell populations, thereby obscuring important cellular nuances and rare cell populations that are critical for understanding stem cell biology [13]. The ability to analyze individual cells reveals diverse cell types, dynamic cellular states, and rare stem cell populations, providing unprecedented resolution for unraveling cellular heterogeneity and complexity [13].
Single-cell technology is particularly valuable for stem cell research because it facilitates non-invasive analyses of molecular dynamics and cellular functions over time [12]. This perspective is crucial for advancing stem cell research, especially given the various heterogeneities present among stem cell sources that have hindered their widespread clinical utilization [12]. Furthermore, stem cell research is intimately connected with cutting-edge technologies such as microfluidic organoids, CRISPR technology, and cell/tissue engineering, with single-cell approaches providing the analytical framework to understand these complex systems [12].
Transcriptomics Technologies
Single-cell RNA sequencing (scRNA-seq) technologies represent the foundation of single-cell analysis, with approaches primarily based on microfluidic chips, microdroplets, and microwell-based systems [14]. The main experimental workflow involves preparing single-cell suspensions, isolating individual cells, capturing mRNA, performing reverse transcription and nucleic acid amplification, and finally constructing transcriptome libraries [14]. Among the most prominent methodologies are:
- Droplet-based technologies (10X Genomics Chromium, Drop-seq) that use beads to capture RNA within oil droplets, creating reaction droplets with high throughput and cost-effectiveness [13].
- Plate-based methods (CEL-seq2, MARS-seq2.0) that provide enhanced sensitivity through linear amplification and barcoding strategies [13].
- Full-length transcript methods (SMART-seq3, FLASH-seq) that utilize template-switching oligos to create full-length cDNA libraries, enabling identification of 5' ends of transcripts and isoform characterization [13].
A critical advancement in scRNA-seq data analysis involves proper data transformation to handle the heteroskedastic nature of count data. The shifted logarithm transformation with a carefully chosen pseudo-count (e.g., ( \log(y/s + y0) ) where ( y0 = 1/(4\alpha) ) based on typical overdispersion ( \alpha )) has been shown to perform as well or better than more sophisticated alternatives for subsequent statistical analysis [15].
Proteomics and Multi-omics Integration
While transcriptomics reveals gene activity patterns, single-cell proteomics provides crucial phenotypic information by quantifying protein abundance [5]. Antibody-based single-cell proteomics, particularly methods such as CITE-seq, ECCITE-seq, and Abseq, leverage the specific binding of antibodies to target proteins to precisely quantify protein expression, revealing cellular heterogeneity and functional diversity [5]. These technologies employ oligonucleotide-labeled antibodies to simultaneously quantify mRNA and surface protein levels in individual cells, generating paired transcriptomic and proteomic datasets from the same cellular microenvironment [5].
The emerging field of single-cell multimodal omics integrates information across diverse molecular dimensions within a single cell, providing a holistic view of biological processes [13]. This approach illuminates the interconnected networks that shape cell behavior and enables identification of causal relationships between omics layers, revealing how genetics affect gene expression, epigenetics, proteins, and metabolites [13]. This integrative perspective is particularly valuable for dissecting complex diseases and understanding stem cell differentiation pathways.
Benchmarking Clustering Algorithms for Stem Cell Population Identification
Experimental Framework and Performance Metrics
The comprehensive benchmarking of clustering algorithms for single-cell data requires a structured experimental framework. Recent studies have evaluated computational methods using datasets with varying characteristics, including: (i) varying numbers of true cell types (5-20) with fixed cells per type; (ii) varying numbers of cells per type (50-250) with fixed cell type numbers; and (iii) varying ratios between major and minor cell types (2:1, 4:1, 10:1) [6]. These datasets are typically sourced from well-characterized references such as Tabula Muris, Tabula Sapiens, or Human Cell Atlas projects [6].
Performance evaluation employs multiple metrics to assess different aspects of clustering quality:
- Clustering Accuracy (CA): Measures the proportion of correctly clustered cells against known labels [5]
- Adjusted Rand Index (ARI): Quantifies clustering quality by comparing predicted and ground truth labels, with values from -1 to 1 [5]
- Normalized Mutual Information (NMI): Measures mutual information between clustering and ground truth, normalized to [0,1] [5]
- Purity: Assesses the extent to which clusters contain cells from single classes [5]
- Computational Efficiency: Peak memory usage and running time [5]
For robust evaluation, studies often employ stability-based approaches that assess clustering robustness to data perturbations, with the assumption that clustering using the optimal number of clusters would be most robust to small perturbations introduced by random resampling [6].
Comparative Performance Across Omics Modalities
A comprehensive 2025 benchmarking study evaluated 28 clustering algorithms across 10 paired single-cell transcriptomic and proteomic datasets, encompassing over 50 cell types and more than 300,000 cells [5]. The algorithms were categorized into three methodological approaches: classical machine learning-based methods (SC3, CIDR, TSCAN, etc.), community detection-based methods (PARC, Leiden, Louvain, etc.), and deep learning-based methods (DESC, scDCC, scGNN, etc.) [5].
Table 1: Top-Performing Clustering Algorithms for Single-Cell Data
| Algorithm | Transcriptomics Ranking | Proteomics Ranking | Method Category | Strengths |
|---|---|---|---|---|
| scAIDE | 2 | 1 | Deep Learning | Top performance across omics, excellent robustness |
| scDCC | 1 | 2 | Deep Learning | High accuracy, memory efficiency |
| FlowSOM | 3 | 3 | Machine Learning | Excellent robustness, balanced performance |
| CarDEC | 4 | 16 | Deep Learning | Good in transcriptomics, less suited for proteomics |
| PARC | 5 | 18 | Community Detection | Fast, but modality-specific performance |
Table 2: Performance Characteristics by Algorithm Category
| Method Category | Representative Algorithms | Performance Strengths | Computational Efficiency |
|---|---|---|---|
| Deep Learning | scDCC, scAIDE, scDeepCluster | High accuracy across modalities, robust to noise | Variable (scDCC and scDeepCluster memory efficient) |
| Machine Learning | FlowSOM, TSCAN, SHARP | Fast processing, interpretable results | Excellent time efficiency (TSCAN, SHARP, MarkovHC) |
| Community Detection | PARC, Leiden, Louvain | Good balance of speed and accuracy | Fast, efficient for large datasets |
The benchmarking revealed that deep learning-based methods generally achieved superior performance for both transcriptomic and proteomic data, with scAIDE, scDCC, and FlowSOM demonstrating the strongest cross-modal performance [5]. Interestingly, some methods that performed well on transcriptomic data (CarDEC, PARC) showed significantly reduced performance on proteomic data, highlighting the modality-specific strengths of certain algorithms [5].
Performance variations between transcriptomic and proteomic data can be attributed to their distinct data distributions and feature dimensionalities [5]. Proteomic data often exhibit different characteristics that pose non-trivial challenges for applying clustering techniques uniformly across both modalities [5].
Experimental Protocols for Algorithm Benchmarking
Standardized Workflow for Single-Cell Data Processing
To ensure reproducible benchmarking results, a standardized preprocessing workflow is essential. The following protocol outlines the key steps for single-cell data processing prior to clustering:
Data Filtering and Quality Control
- Filter cells with minimum of 2000 non-zero transcripts
- Exclude cells with ≥5% mitochondrial transcripts or ≤10% ribosomal transcripts
- Remove transcripts not present in at least 3 cells [16]
Normalization and Transformation
- Normalize counts to counts per million (CPM) for each cell
- Apply log base 2 transformation with an offset of 1
- Scale normalized data across single cells to mean expression = 0 and variance = 1 [16]
Feature Selection and Dimensionality Reduction
- Select highly variable genes using variance-stabilizing transformation
- Perform principal component analysis (PCA) to reduce data dimensionality
- Determine the number of principal components using the Kneedle heuristic to identify the point of maximum curvature of explained variance [16]
Graph Construction and Clustering
- Construct k-nearest neighbor graph (typically k=100) with edges representing distances between cells
- Apply Leiden algorithm with resolution of 0.8 to group single cells into clusters [16]
- Visualize clusters in UMAP space for quality assessment
This workflow is implemented in tools such as Scanpy (Python) or Seurat (R), which provide standardized pipelines for single-cell data analysis [14].
Cross-Modal Integration Protocols
For multi-omics data integration, recent benchmarking studies have employed state-of-the-art integration methods including moETM, sciPENN, scMDC, totalVI, and MOFA+ [5]. The integration protocol typically involves:
- Paired Data Processing: Process transcriptomic and proteomic data from the same cells using matched barcodes
- Modality-Specific Normalization: Apply appropriate normalization for each data type (e.g., log(CPM+1) for RNA, arcsinh transformation for protein)
- Feature Integration: Use integration algorithms to align the different modalities in a shared latent space
- Joint Clustering: Apply clustering algorithms to the integrated features to identify cell populations
The performance of clustering on integrated data is then compared to clustering performed on individual modalities to assess the value of multi-omics integration [5].
Research Reagent Solutions for Single-Cell Studies
Table 3: Essential Research Reagents and Platforms for Single-Cell Stem Cell Research
| Product Category | Specific Examples | Application in Single-Cell Research |
|---|---|---|
| Cell Culture Media | eTeSR, TeSR-AOF 3D | Maintain pluripotent stem cells in undifferentiated state for single-cell studies |
| Differentiation Kits | STEMdiff Cardiomyocyte Expansion Kit, STEMdiff Microglia Culture System | Generate specific cell types from stem cells for heterogeneity analysis |
| Extracellular Matrices | STEMmatrix BME | Provide physiological 3D environment for stem cell growth and differentiation |
| Cell Separation | ImmunoCult-XF, ImmunoCult Human T Cell Activators | Isle and expand specific immune cell populations from differentiated cultures |
| Bioreactor Systems | PBS-MINI Bioreactor | Scale up 3D cell cultures for large-scale single-cell sequencing projects |
Visualization of Single-Cell Data Analysis Workflow
Single-Cell Analysis Workflow
The benchmarking of clustering algorithms for single-cell data in stem cell research reveals that while deep learning methods generally provide superior performance, the choice of algorithm depends on specific research goals, data modalities, and computational constraints. The field continues to evolve rapidly with emerging trends including:
- Improved multi-omics integration methods that better capture interactions between molecular layers
- Spatial transcriptomics technologies that preserve spatial context in single-cell analysis
- Temporal dynamics inference through computational methods such as RNA velocity and pseudotime analysis
- Automated cell type annotation tools that leverage reference atlases for consistent cell labeling
For stem cell researchers, the selection of clustering algorithms should consider both performance metrics and practical constraints. scAIDE, scDCC, and FlowSOM represent strong choices for cross-modal applications, while TSCAN and SHARP offer efficient solutions for transcriptomic-specific analyses [5]. As single-cell technologies continue to mature, standardized benchmarking approaches will be increasingly important for ensuring rigorous and reproducible stem cell research.
Single-cell RNA-sequencing (scRNA-seq) has revolutionized stem cell biology by enabling researchers to investigate cellular heterogeneity, lineage commitment, and plasticity at unprecedented resolution. A critical step in analyzing scRNA-seq data involves unsupervised clustering, which partitions cells into distinct subpopulations based on their transcriptomic profiles. Accurate clustering is fundamental for identifying rare stem cell populations, tracking differentiation trajectories, and understanding plasticity mechanisms. This guide objectively compares the performance of various clustering algorithms specifically within the context of stem cell research, providing experimental data and methodologies to inform algorithm selection for specific applications. Benchmarking studies reveal that method choice significantly impacts biological interpretations, as different algorithms exhibit varying strengths in detecting subtle population structures, estimating cluster numbers, and handling the unique characteristics of stem cell datasets [17] [18].
Benchmarking Clustering Algorithms for Stem Cell Applications
Performance Evaluation on Real and Simulated Data
Systematic benchmarking efforts evaluate clustering algorithms using multiple metrics on real and simulated datasets. Key performance indicators typically include:
- Adjusted Rand Index (ARI): Measures the similarity between computational clustering results and biological ground truth labels.
- Normalized Mutual Information (NMI): Quantifies the mutual dependence between predicted clusters and reference cell types.
- Running Time and Peak Memory Usage: Assess computational efficiency and scalability [5] [18].
These evaluations employ datasets with known cell type labels to objectively quantify accuracy. For instance, studies often use the Tabula Muris dataset, which contains carefully annotated cell types from mouse tissues, to create benchmark datasets with varying numbers of cell types (5-20), different cells per type (50-250), and different proportions of major and minor populations [18]. This approach tests algorithm performance under controlled conditions that mimic the challenges of stem cell research.
Table 1: Top-Performing Clustering Algorithms Across Single-Cell Modalities
| Algorithm | Transcriptomic Data Ranking | Proteomic Data Ranking | Key Strengths | Computational Efficiency |
|---|---|---|---|---|
| scAIDE | 2nd | 1st | High performance across omics | Moderate |
| scDCC | 1st | 2nd | Excellent generalization | Memory efficient |
| FlowSOM | 3rd | 3rd | Robustness, fast running time | Time and memory efficient |
| Seurat | Variable | Variable | Handlers large datasets | Moderate |
| SC3 | Variable | N/A | User-friendly | High memory usage |
Performance Variation Across Data Modalities
Clustering performance can vary significantly between transcriptomic and proteomic data. A 2025 benchmark evaluating 28 algorithms on 10 paired transcriptomic and proteomic datasets found that scDCC, scAIDE, and FlowSOM consistently ranked highest for both modalities, demonstrating strong generalization capabilities [5]. However, some methods exhibited modality-specific performance; for example, CarDEC and PARC ranked 4th and 5th respectively in transcriptomics but dropped significantly to 16th and 18th in proteomics [5]. This highlights the importance of selecting algorithms validated for specific data types in stem cell research.
Algorithm robustness is another critical consideration. Benchmarking using 30 simulated datasets with varying noise levels and dataset sizes identified FlowSOM as particularly robust, maintaining stable performance under different data quality conditions [5]. For users with specific computational constraints, scDCC and scDeepCluster are recommended for memory efficiency, while TSCAN, SHARP, and MarkovHC excel in time efficiency [5].
Application 1: Identifying Rare Stem Cell Populations
Technical Challenges and Algorithm Selection
Rare stem cell populations, such as cancer stem cells or quiescent tissue-specific stem cells, often constitute a small fraction of the total cell population but play critical roles in development, homeostasis, and disease. Identifying these rare populations presents particular challenges: their transcriptomic signatures may be obscured by more abundant cell types, and standard clustering approaches may fail to resolve these subtle differences.
Specialized clustering approaches have been developed to address these challenges. RaceID was specifically designed to identify rare cell types by introducing a statistical test to compare within-cluster dispersion, enabling detection of outliers that may represent rare populations [18]. SC3 employs consensus clustering combined with eigenvalue analysis based on the Tracy-Widom test, enhancing its sensitivity to small but biologically relevant subpopulations [18]. Benchmarking studies have revealed that algorithms differ significantly in their ability to correctly estimate the number of cell types in a dataset—a crucial prerequisite for rare population identification [18].
Table 2: Algorithm Performance in Estimating Number of Cell Types
| Algorithm | Tendency | Stability | Notable Characteristics |
|---|---|---|---|
| Monocle3 | Minimal deviation | High | Community detection-based |
| scLCA | Minimal deviation | High | Uses Silhouette index |
| scCCESS-SIMLR | Minimal deviation | Moderate | Stability-based approach |
| SC3 | Overestimation | Moderate | Consensus clustering |
| Seurat | Overestimation | Moderate | Handles large datasets well |
| SHARP | Underestimation | High | Uses multiple indices |
| densityCut | Underestimation | Moderate | Density-based |
| Spectrum | High variability | Low | Eigengap heuristic |
Experimental Protocol for Rare Population Identification
A typical workflow for identifying rare stem cell populations includes:
- Data Preprocessing: Quality control, normalization, and feature selection using highly variable genes (HVGs). The number of HVGs significantly impacts clustering performance and should be optimized for each dataset [5].
- Dimensionality Reduction: Application of PCA or other techniques to reduce computational complexity and noise.
- Clustering Analysis: Implementation of rare cell-sensitive algorithms like RaceID or SC3 with appropriate parameters.
- Validation: Experimental validation using fluorescence-activated cell sorting (FACS) with stem cell markers or functional assays such as transplantation studies [19].
For hematopoietic stem cells (HSCs), which are particularly rare, researchers have successfully combined antibody-based isolation with single-cell transcriptomics to resolve previously unrecognized heterogeneity within this population [20]. This integrated approach has revealed that putatively homogeneous stem cell populations actually contain subpopulations with distinct functional characteristics and differentiation potentials.
Application 2: Tracking Stem Cell Differentiation
Lineage Trajectory Reconstruction
Stem cell differentiation involves progressive restriction of developmental potential, culminating in specialized cell types. Tracking this process requires computational approaches that can reconstruct developmental trajectories from snapshots of single-cell data. Pseudotemporal ordering methods have been particularly valuable in this context, as they order cells based on transcriptomic similarities to reconstruct the longest continuous path through a high-dimensional space, effectively recreating the differentiation timeline [20].
Studies using single-cell transcriptomics have revealed that lineage commitment often begins with stochastic fluctuations in the expression of lineage-affiliated genes in multipotent stem cells—a phenomenon known as "lineage priming" [20]. As differentiation progresses, cells transition through a hierarchical series of commitment steps before stabilizing a specific lineage program.
Experimental Workflow for Tracking Differentiation
Figure 1: Experimental workflow for tracking stem cell differentiation using viral barcoding and high-throughput sequencing.
Advanced experimental methods combine viral genetic barcoding with high-throughput sequencing to track single cells in heterogeneous populations [19]. The methodology involves:
- Viral Barcoding: A lentiviral library containing semi-random 33mer DNA barcodes is used to infect stem cells at a low multiplicity of infection (MOI~1) to ensure most cells receive a single barcode [19].
- Transplantation/Differentiation: Barcoded cells are transplanted into host organisms or induced to differentiate in vitro.
- Time-Series Sampling: Cells are collected at multiple time points during differentiation.
- Sequencing and Barcode Recovery: Genomic DNA is extracted, barcodes are recovered via PCR, and high-throughput sequencing identifies barcodes present in different cell populations [19].
- Clonal Analysis: Bioinformatic analysis reconstructs differentiation trees based on barcode sharing between cell populations.
This approach has revealed that stem cells do not contribute equally to differentiation—some HSCs generate balanced output across lineages while others show distinct differentiation biases [19].
Application 3: Understanding Stem Cell Plasticity
Defining and Measuring Plasticity
Stem cell plasticity refers to the capacity of stem cells to switch lineages, dedifferentiate, or transdifferentiate in response to environmental cues. While traditionally, differentiation was viewed as a unidirectional process, single-cell studies have revealed remarkable flexibility in cell identity, particularly in cancer stem cells and during cellular reprogramming.
The core molecular regulators of plasticity include:
- Pluripotency Factors: Oct4, Sox2, and Nanog maintain pluripotency in embryonic stem cells through a complex network of mutual regulation and co-occupation of target gene promoters [21].
- EMT/MET Regulators: Epithelial-mesenchymal transition (EMT) and its reverse (MET) are crucial for plasticity, with transcription factors like Snail, Zeb, and Twist acting as repressors of the epithelial phenotype and inducers of mesenchymal characteristics [21].
- Epigenetic Modifiers: DNA methylation and histone modification states significantly influence lineage potential, with small molecule epigenetic manipulators capable of enhancing or restricting differentiation capacity [22].
Signaling Pathways Regulating Plasticity
Figure 2: Signaling pathways and molecular regulators of stem cell plasticity.
Experimental approaches for investigating plasticity include:
- Lineage Tracing: Genetic labeling of specific cell populations followed by fate mapping.
- Reprogramming Assays: Introduction of pluripotency factors (Oct4, Klf4, Sox2, c-Myc) to induce dedifferentiation.
- Single-Cell Multi-omics: Simultaneous measurement of transcriptomic and epigenomic states in individual cells.
- Clonal Analysis: Tracking the fate of individual stem cells and their progeny over time.
Researchers have discovered that the reprogramming of somatic cells into induced pluripotent stem cells (iPSCs) requires a MET, highlighting the intimate connection between plasticity and epithelial phenotype [21]. Small molecule epigenetic manipulators—such as Gemcitabine and Chidamide—can significantly enhance osteogenic differentiation in aged human mesenchymal stem cells by 5.9- and 2.3-fold respectively, demonstrating how epigenetic modifications can overcome age-related declines in plasticity [22].
The Scientist's Toolkit: Essential Research Reagents and Computational Tools
Table 3: Essential Research Reagents and Computational Tools for Stem Cell Clustering
| Category | Specific Tool/Reagent | Function/Application | Considerations |
|---|---|---|---|
| Wet-Lab Reagents | Lentiviral Barcode Library | Single-cell lineage tracing | Ensure single-cell representation [19] |
| Oligonucleotide-labeled Antibodies | CITE-seq for paired transcriptomics/proteomics | Enables multi-modal clustering [5] | |
| Epigenetic Molecules | Modulating lineage potential | Specificity for lineages varies [22] | |
| Computational Tools | Seurat | Comprehensive scRNA-seq analysis | Shows variable estimation performance [18] |
| SC3 | Consensus clustering | Tendency for overestimation [18] | |
| Monocle3 | Trajectory inference | Accurate cell type number estimation [18] | |
| FlowSOM | Clustering for proteomic data | Excellent robustness across modalities [5] |
Clustering algorithms play an indispensable role in unlocking the complexities of stem cell biology, from rare population identification to differentiation tracking and plasticity assessment. Benchmarking studies consistently identify scDCC, scAIDE, and FlowSOM as top-performing methods across multiple modalities and evaluation metrics, providing excellent starting points for researchers. However, algorithm performance is context-dependent—methods excelling at estimating cluster numbers (e.g., Monocle3, scLCA) may differ from those optimal for rare population detection (e.g., RaceID, SC3).
Future developments will likely focus on multi-omics integration, dynamic trajectory inference, and machine learning approaches that can better capture the complexity of stem cell systems. As single-cell technologies continue to evolve, with methods now enabling simultaneous profiling of transcriptomics, proteomics, and epigenomics in the same cells, clustering algorithms must similarly advance to leverage these rich, multi-dimensional datasets. The integration of computational clustering with advanced experimental techniques—particularly viral barcoding and epigenetic manipulation—will continue to drive fundamental discoveries in stem cell biology and accelerate the development of stem cell-based therapies.
Comparative Analysis of Clustering Algorithms: Performance Across Stem Cell Datasets
The identification of distinct stem cell subpopulations is crucial for advancing regenerative medicine and understanding cellular differentiation pathways. This process relies heavily on computational clustering algorithms to decipher complex single-cell data. As research progresses, three major algorithmic categories have emerged as fundamental tools: Classical Machine Learning, Community Detection, and Deep Learning approaches. Each category offers distinct methodologies and advantages for tackling the challenges of stem cell heterogeneity analysis.
Classical machine learning algorithms provide well-established, interpretable frameworks for cell type identification. Community detection methods, originally developed for network analysis, excel at uncovering functional modules within cellular interaction networks. Deep learning approaches offer superior pattern recognition capabilities for high-dimensional data, enabling the identification of subtle morphological and transcriptomic differences between stem cell states. The integration of these computational approaches with systems biology and artificial intelligence (SysBioAI) is transforming stem cell research by enabling holistic analysis of multi-omics datasets and accelerating therapeutic development [23].
This guide provides an objective comparison of these algorithm categories within the specific context of benchmarking studies for stem cell subpopulation identification, presenting experimental data and methodologies to inform researchers' selection of appropriate computational tools.
Performance Comparison of Algorithm Categories
Comprehensive Benchmarking Across Algorithm Types
Table 1: Overall Performance Characteristics of Algorithm Categories
| Algorithm Category | Representative Methods | Key Strengths | Key Limitations | Computational Efficiency |
|---|---|---|---|---|
| Classical Machine Learning | SVM, Random Forest, SC3, TSCAN | High interpretability, robust with smaller datasets, minimal hyperparameter tuning | Limited capacity for very high-dimensional data, may miss complex nonlinear patterns | Moderate to high (varies by method) |
| Community Detection | Louvain, Leiden, PARC, PhenoGraph | Effective for network-structured data, identifies hierarchical communities | Stochasticity leads to variability, requires resolution parameter selection | High (for most methods) |
| Deep Learning | scDCC, scAIDE, scGNN, DESC | Superior handling of high-dimensional data, automated feature learning, high accuracy | High computational demand, requires large datasets, "black box" nature | Variable (often resource-intensive) |
Table 2: Quantitative Performance Metrics from Benchmarking Studies
| Algorithm Category | Top Performers | Average ARI* | Average NMI* | Scalability to Large Datasets | Handling of Batch Effects |
|---|---|---|---|---|---|
| Classical ML | SVM, Random Forest | 0.72-0.85 | 0.75-0.88 | Moderate | Moderate |
| Community Detection | Leiden, Louvain | 0.68-0.82 | 0.71-0.85 | High | Limited |
| Deep Learning | scAIDE, scDCC, FlowSOM | 0.78-0.92 | 0.81-0.94 | Variable (improving) | Good to excellent |
*ARI (Adjusted Rand Index) and NMI (Normalized Mutual Information) are similarity measures between clustering results and ground truth, where values closer to 1 indicate better performance [24].
Benchmarking studies evaluating 28 computational algorithms on paired transcriptomic and proteomic datasets have revealed that deep learning methods generally achieve superior performance metrics, with scAIDE, scDCC, and FlowSOM ranking as top performers across multiple evaluation criteria [24]. However, classical machine learning approaches like SVM have demonstrated exceptional consistency, emerging as top performers in three out of four datasets in cell annotation tasks [25].
Community detection algorithms like Leiden and Louvain remain widely adopted due to their speed and efficiency in processing large single-cell datasets, though they exhibit stochasticity that can lead to variability in results across different runs [26]. The recently developed scICE framework addresses this limitation by evaluating clustering consistency, achieving up to 30-fold improvement in speed compared to conventional consensus clustering-based methods [26].
Performance in Stem Cell Research Applications
Table 3: Algorithm Performance in Specific Stem Cell Applications
| Application Domain | Recommended Algorithms | Performance Notes | Key Experimental Findings |
|---|---|---|---|
| Hematopoietic Stem/Progenitor Cell Identification | Deep Learning (LSM model), SVM, FlowSOM | DL achieved >90% accuracy distinguishing LT-HSCs, ST-HSCs, MPPs | DL models successfully classified HSC subpopulations based solely on morphological features from DIC images [27] |
| Mesenchymal Stem Cell Characterization | scAIDE, Random Forest, Leiden | Integration of multi-omics data enhances subpopulation resolution | SysBioAI approaches enable iterative refinement of stem cell therapeutic products [23] |
| Cancer Stem Cell Identification | GNN-based approaches, SVM, PhenoGraph | DL identifies subtle transcriptomic subpopulations from morphology | CNNs discriminated breast cancer subpopulations with AUC 0.74-0.8 using phase contrast images [28] |
| Rare Stem Cell Population Detection | scICE, SVM, scDCC | Specialized frameworks improve consistency for rare cell identification | Ensemble approaches combining multiple algorithms enhance rare cell type discovery [26] [25] |
In functional subpopulation classification of hematopoietic stem cells, deep learning approaches have demonstrated remarkable capability by distinguishing long-term HSCs, short-term HSCs, and multipotent progenitors based solely on morphological features observed through light microscopy images [27]. This deep learning-based platform provided proof-of-principle for antibody-free identification of different cell populations purely based on cell morphology, potentially obviating the need for time-consuming transplantation experiments for functional assessment.
For stem cell research requiring integration of multiple data modalities, systems biology approaches combining AI and multi-omics data analysis have shown particular promise. The iterative circle of refined clinical translation concept leverages SysBioAI to optimize both therapeutic products and clinical trial strategies through continuous adaptation cycles [23].
Experimental Protocols and Methodologies
Standardized Benchmarking Framework
To ensure fair comparison across algorithm categories, benchmarking studies should implement standardized experimental protocols:
Data Preprocessing Pipeline:
- Quality Control: Filtering low-quality cells and genes using standardized thresholds
- Normalization: Apply appropriate normalization methods (e.g., logCPM for transcriptomic data)
- Feature Selection: Identify highly variable genes (HVGs) or relevant features
- Dimensionality Reduction: Implement PCA, scLENS [26], or other reduction techniques
- Graph Construction: Build k-nearest neighbor graphs for community detection approaches
Evaluation Methodology:
- Multiple Datasets: Utilize diverse datasets representing different stem cell types and tissues
- Ground Truth Validation: Use experimentally validated cell labels when available
- Multiple Metrics: Employ ARI, NMI, clustering accuracy, purity, and runtime assessment
- Consistency Testing: Execute multiple runs with different random seeds to assess stability
- Statistical Analysis: Perform appropriate statistical tests to determine significance of performance differences
The benchmarking study of 28 clustering algorithms implemented this rigorous approach across 10 paired transcriptomic and proteomic datasets encompassing over 50 cell types and more than 300,000 cells [24]. This comprehensive evaluation revealed that approximately 30% of clustering attempts across different algorithm classes produced consistent results, highlighting the importance of robust benchmarking [26].
Deep Learning Model Training Protocol
For deep learning approaches in stem cell research, the following experimental protocol has proven effective:
Network Architecture Selection:
- Convolutional Neural Networks (CNNs): For image-based stem cell classification [27] [28]
- Graph Neural Networks (GNNs): For network-structured single-cell data [29] [30]
- Autoencoders: For dimensionality reduction and feature learning [29]
Training Procedure:
- Data Partitioning: Split data into training (80%), validation (10%), and test sets (10%)
- Data Augmentation: Apply appropriate augmentation techniques (rotation, flipping for images; noise injection for omics data)
- Model Initialization: Use pre-trained weights when available (transfer learning)
- Optimization: Employ adaptive learning rate methods (Adam, SGD with momentum)
- Regularization: Implement dropout, weight decay, and early stopping to prevent overfitting
- Validation: Monitor performance on validation set throughout training
In the hematopoietic stem cell study, researchers developed a three-class classifier (LSM model) using extensive image datasets after rigorous training and validation [27]. The model extracted intrinsic morphological features unique to different cell types, independent of surface markers or intracellular GFP markers used for initial identification and isolation.
Consistency Evaluation Framework
For assessing clustering reliability across algorithm categories, the scICE framework provides a robust methodology:
Inconsistency Coefficient Calculation:
- Multiple Clustering Runs: Execute clustering algorithm multiple times with different random seeds
- Similarity Matrix Construction: Compute element-centric similarity between all label pairs
- Probability Estimation: Determine occurrence probability of each unique label
- IC Calculation: Compute inconsistency coefficient using IC = 1/(pSpᵀ) where p represents probability vector and S is similarity matrix
Implementation Details:
- Parallel processing across multiple cores to reduce computation time
- Application across various resolution parameters
- Identification of consistent cluster labels for downstream analysis
This approach has demonstrated up to 30-fold speed improvement compared to conventional consensus clustering-based methods while effectively identifying reliable clustering results [26].
Essential Research Reagents and Computational Tools
Research Reagent Solutions for Stem Cell Analysis
Table 4: Essential Research Reagents for Stem Cell Isolation and Characterization
| Reagent Category | Specific Examples | Application in Stem Cell Research | Function in Experimental Protocols |
|---|---|---|---|
| Surface Marker Antibodies | CD150, CD48, CD34, CD135, Sca-1, c-Kit | Hematopoietic stem cell isolation and characterization | Cell sorting and population validation via flow cytometry [27] |
| Intracellular Markers | α-catulin, Evi1, GFP reporters | Stem cell tracking and functional assessment | Genetic labeling of stem cell populations for lineage tracing [27] |
| Cell Staining Reagents | Lineage cocktail antibodies, viability dyes | Sample preparation for single-cell analysis | Cell identification and removal of dead cells [27] |
| Single-Cell Sequencing Kits | 10x Genomics, CITE-seq reagents | Transcriptomic and proteomic profiling | Simultaneous measurement of mRNA and surface protein levels [24] |
Computational Tools and Frameworks
Table 5: Essential Computational Tools for Algorithm Implementation
| Tool Category | Specific Software/Packages | Algorithm Support | Key Applications |
|---|---|---|---|
| Comprehensive Platforms | Seurat, Scanpy, Monocle3 | All categories | End-to-end single-cell data analysis [24] [26] |
| Classical ML Implementation | scikit-learn, SC3, TSCAN | Classical ML | Cell type annotation, clustering [24] [25] |
| Community Detection | Leiden, Louvain, PARC | Community Detection | Graph-based clustering, network analysis [24] [26] |
| Deep Learning Frameworks | PyTorch, TensorFlow, scDCC, scAIDE | Deep Learning | Complex pattern recognition, image analysis [24] [27] |
| Benchmarking Tools | scICE, multiK, chooseR | All categories | Clustering consistency evaluation [26] |
The selection of appropriate computational tools depends on the specific research question and data characteristics. For rapid analysis of large datasets, community detection methods implemented in Seurat or Scanpy provide efficient solutions. For more complex pattern recognition tasks involving morphological data or multi-omics integration, deep learning approaches offer superior performance despite higher computational requirements [27] [28].
The comparative analysis of classical machine learning, community detection, and deep learning approaches for stem cell subpopulation identification reveals a complex landscape where each algorithm category offers distinct advantages depending on the specific research context.
Classical machine learning methods, particularly SVM and Random Forest, provide robust, interpretable solutions for standard classification tasks and remain competitive in many benchmarking studies [25]. Community detection algorithms excel in processing large-scale single-cell datasets efficiently, though their stochastic nature requires consistency validation frameworks like scICE [26]. Deep learning approaches demonstrate superior performance in handling high-dimensional data and complex pattern recognition tasks, particularly for image-based stem cell classification and multi-omics integration [27] [28].
The integration of these computational approaches with SysBioAI frameworks presents a promising direction for future stem cell research, enabling iterative refinement of therapeutic products and clinical translation strategies [23]. As the field advances, the development of more efficient, interpretable, and adaptable algorithms will further enhance our ability to unravel stem cell heterogeneity and accelerate the development of regenerative therapies.
Researchers should select algorithms based on their specific data characteristics, computational resources, and research objectives, leveraging benchmarking studies and consistency evaluation tools to ensure robust and reproducible results in stem cell subpopulation identification.
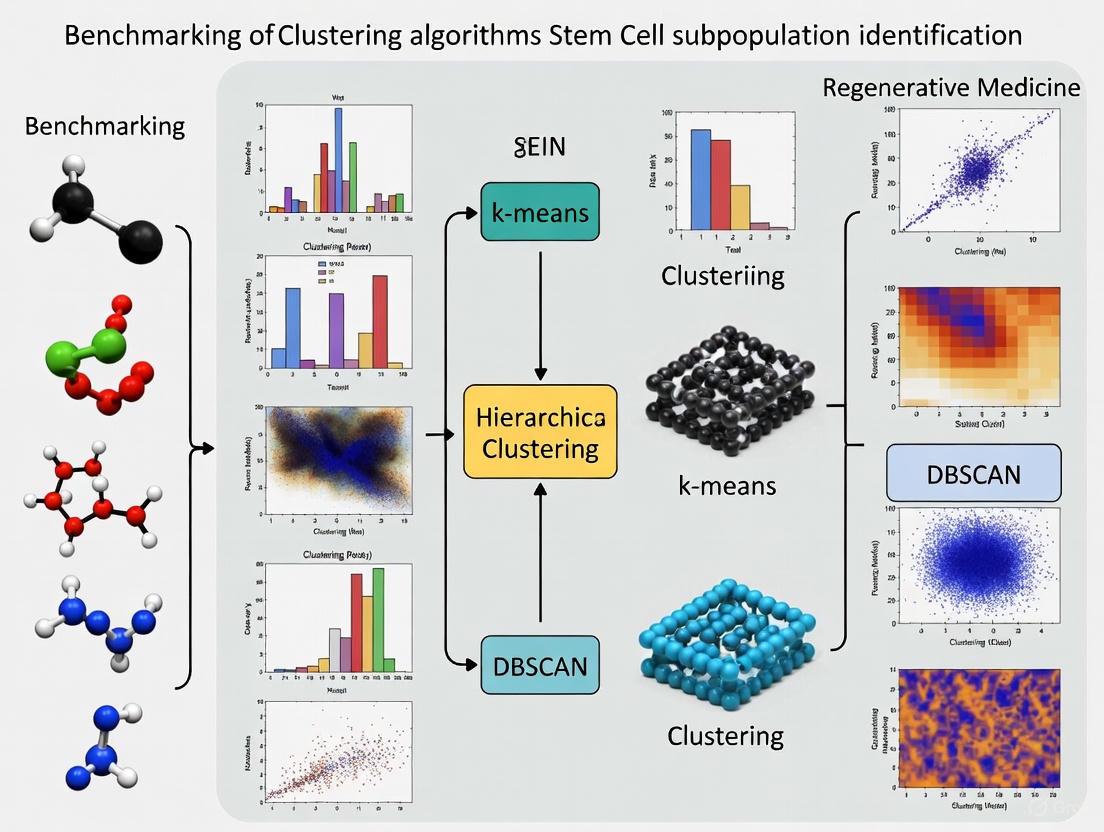
Single-cell RNA sequencing (scRNA-seq) has revolutionized stem cell research by enabling the detailed dissection of cellular heterogeneity within populations. A fundamental step in this analysis is clustering, which groups cells with similar gene expression profiles to identify distinct cell types, states, and transitional populations. The selection of an appropriate clustering algorithm directly impacts the reliability of downstream biological interpretations, from discovering novel stem cell subtypes to understanding differentiation trajectories. Recent comprehensive benchmarking studies have systematically evaluated computational methods for clustering single-cell data across different omics modalities, including transcriptomics and proteomics. These studies reveal that despite the proliferation of available methods, three algorithms—scAIDE, scDCC, and FlowSOM—consistently demonstrate superior performance for transcriptomic and proteomic data, making them particularly promising candidates for the complex analysis of stem cell populations [31] [5]. This guide provides an objective comparison of these top-performing methods based on experimental data, offering stem cell researchers evidence-based recommendations for their analytical workflows.
Benchmarking Methodology and Evaluation Metrics
The performance data presented in this guide originates from a large-scale benchmark study published in Genome Biology (2025), which comprehensively evaluated 28 clustering algorithms on 10 paired transcriptomic and proteomic datasets [31] [5]. The benchmarking framework employed multiple validation metrics to ensure robust assessment:
- Clustering Quality Metrics: Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Clustering Accuracy (CA), and Purity were used to quantify how well the computational clusters matched established biological labels [5].
- Computational Efficiency Metrics: Peak memory usage and running time were measured to assess practical performance requirements [31].
- Robustness Evaluation: Algorithms were tested on 30 simulated datasets with varying noise levels and dataset sizes to evaluate their stability under different conditions [5].
- Multi-Omics Integration: The study also assessed how these methods performed on integrated transcriptomic and proteomic data using seven state-of-the-art integration methods [5].
The benchmarking study ranked algorithms based on their overall performance across both transcriptomic and proteomic data. The following table summarizes the key findings for the top performers:
Table 1: Overall Performance Ranking of Top Clustering Algorithms
| Algorithm | Overall Rank (Transcriptomics) | Overall Rank (Proteomics) | Key Strengths | Computational Profile |
|---|---|---|---|---|
| scAIDE | 2 | 1 | Top performance in proteomics, robust across modalities | Moderate resource usage |
| scDCC | 1 | 2 | Best in transcriptomics, memory efficient | High memory efficiency |
| FlowSOM | 3 | 3 | Excellent robustness, balanced performance | Fast, memory efficient |
This comprehensive evaluation revealed that scAIDE, scDCC, and FlowSOM formed a distinct top tier of performers, significantly outperforming other methods in clustering accuracy and consistency across diverse data types [5]. While the benchmark did not exclusively use stem cell datasets, the consistent performance across multiple tissue types and biological systems suggests strong generalizability to stem cell research applications.
Detailed Algorithm Analysis
scAIDE: Advanced Deep Learning Framework
scAIDE (single-cell Autoencoder-Imputed Distance-preserved Embedding) represents a sophisticated deep learning approach specifically designed to address the high noise and dimensionality challenges of single-cell data [32].
Table 2: Technical Specifications of scAIDE
| Aspect | Specification | Biological Relevance |
|---|---|---|
| Architecture | Two-stage neural network: Autoencoder for imputation + MDS encoder for distance preservation | Effectively handles dropout events common in stem cell scRNA-seq |
| Clustering Method | Random Projection Hashing-based k-means (RPH-kmeans) | Identifies rare cell types (e.g., rare stem cell subtypes) |
| Scalability | Analyzed 1.3 million neural cells within 30 minutes | Suitable for large-scale stem cell atlas projects |
| Key Innovation | Distance-preserving embedding coupled with imbalance-aware clustering | Maintains biological relationships while addressing cell population size disparities |
The experimental validation of scAIDE demonstrated exceptional performance in identifying rare cell populations—a critical capability for stem cell research where transitional states or rare subtypes often represent biologically significant populations. In one application, scAIDE successfully identified Cajal-Retzius cells (approximately 1.6% of total population) in a neural dataset, highlighting its sensitivity for detecting minority populations [32]. For stem cell researchers, this sensitivity could translate to improved identification of early differentiation intermediates or rare progenitor cell types.
scDCC: Memory-Efficient Deep Clustering
scDCC represents another deep learning-based approach that excelled in the benchmarking studies, particularly noted for its memory efficiency while maintaining high accuracy [31] [5].
The benchmarking results positioned scDCC as the top performer for transcriptomic data and second-best for proteomic data, indicating its strong cross-modal applicability [5]. This consistency across data types is particularly valuable for stem cell researchers working with multi-omics approaches or integrating datasets from different technologies. While the search results don't provide exhaustive technical details for scDCC, its high ranking in both performance and memory efficiency makes it particularly suitable for research groups with computational constraints or those working with exceptionally large datasets, such as those generated in comprehensive stem cell atlas projects.
FlowSOM: Robust and Efficient Clustering
FlowSOM utilizes a self-organizing map (SOM) approach followed by hierarchical consensus metaclustering, originally developed for cytometry data but demonstrating excellent performance across single-cell omics modalities [5] [33].
Table 3: FlowSOM Performance Characteristics
| Characteristic | Performance | Advantage for Stem Cell Research |
|---|---|---|
| Robustness | Excellent across simulated datasets with varying noise | Reliable performance across different stem cell protocols and quality |
| Sample Size Stability | Maintains consistent performance as sample size increases | Suitable from small pilot studies to large-scale atlas projects |
| Clustering Tendency | Groups similar clusters into meta-clusters | Provides hierarchical view of stem cell differentiation landscape |
| Computational Speed | Fast processing with minimal memory requirements | Enables rapid iterative analysis and parameter optimization |
Previous evaluations of FlowSOM on mass cytometry data have highlighted its precision, coherence, and stability, characteristics that appear to extend to its performance on transcriptomic and proteomic data [33]. The algorithm's tendency to group similar clusters into meta-clusters can be particularly advantageous for understanding the hierarchical organization of stem cell populations, from multipotent progenitors to fully differentiated cell types.
Experimental Protocols and Implementation
Benchmarking Workflow
The experimental workflow used to generate the performance data provides a template for stem cell researchers to validate these methods in their specific contexts.
Diagram 1: Benchmarking Workflow for Clustering Algorithms
Key Research Reagent Solutions
The computational methods evaluated require specific analytical "reagents" or tools for implementation. The following table outlines essential components for reproducing the benchmark analyses:
Table 4: Essential Research Reagent Solutions for Single-cell Clustering
| Reagent Category | Specific Tools/Methods | Function in Analysis |
|---|---|---|
| Quality Control | Scanpy, Seurat | Filtering low-quality cells and genes based on metrics |
| Normalization | LogTPM, SCTransform | Technical noise removal and count normalization |
| Feature Selection | Highly Variable Genes (HVGs) | Identification of informative genes for clustering |
| Dimensionality Reduction | PCA, scLENS | Noise reduction and signal enhancement |
| Integration Methods | moETM, sciPENN, totalVI | Combining multi-omics data for integrated clustering |
| Validation Metrics | ARI, NMI, Clustering Accuracy | Quantitative performance assessment |
The benchmark study emphasized that highly variable gene selection significantly impacts clustering performance, recommending careful attention to this preprocessing step [5]. For stem cell researchers, this suggests that method-specific optimization of HVG selection may further enhance clustering quality for specific biological questions.
Comparative Performance Analysis
Quantitative Performance Across Metrics
The comprehensive benchmarking provides detailed quantitative comparisons across multiple evaluation metrics, offering stem cell researchers actionable data for algorithm selection.
Table 5: Detailed Performance Metrics Across Evaluation Categories
| Algorithm | Clustering Quality (ARI) | Clustering Quality (NMI) | Time Efficiency | Memory Efficiency | Robustness |
|---|---|---|---|---|---|
| scAIDE | High (Top tier) | High (Top tier) | Moderate | Moderate | High |
| scDCC | High (Top tier) | High (Top tier) | Moderate | High (Recommended) | High |
| FlowSOM | High (Top tier) | High (Top tier) | High (Recommended) | High | High (Recommended) |
The data reveals that while all three algorithms excel in clustering quality metrics, they present different trade-offs in computational efficiency. scDCC and FlowSOM offer superior memory efficiency, while FlowSOM also demonstrates excellent time efficiency [31] [5]. The robustness of FlowSOM across varying data conditions makes it particularly suitable for exploratory analysis of stem cell datasets, where data quality and characteristics may vary substantially.
Modality-Specific Performance
A key finding from the benchmark study is that performance varies across data modalities, an important consideration for stem cell researchers working with diverse data types.
Diagram 2: Algorithm Performance Across Data Modalities
For stem cell researchers focusing specifically on transcriptomic data, scDCC provides the highest performance, while those working with proteomic data (such as CITE-seq or antibody-derived tags) would benefit most from scAIDE [5]. All three methods maintain strong performance when applied to integrated multi-omics data, making them future-proof for increasingly comprehensive multi-modal stem cell characterization.
Recommendations for Stem Cell Research Applications
Based on the comprehensive benchmarking data, we provide the following evidence-based recommendations for stem cell researchers:
For maximum clustering accuracy in standard transcriptomic analyses of stem cell populations, scDCC provides the highest performance, particularly valuable when identifying subtle subpopulations or transitional states.
For proteomic data or integrated multi-omics approaches, scAIDE demonstrates superior performance, making it ideal for researchers using CITE-seq or similar technologies that simultaneously capture transcriptomic and proteomic information from stem cells.
For large-scale studies or resource-constrained environments, FlowSOM offers the best balance of performance and computational efficiency, with exceptional robustness across diverse data conditions.
For identifying rare stem cell subtypes, scAIDE's specialized architecture provides enhanced sensitivity for detecting small populations, a critical requirement for characterizing rare progenitor cells or early differentiation intermediates.
The benchmark study further recommends that researchers consider their specific priorities—whether clustering accuracy, memory efficiency, or computational speed—when selecting among these top-performing methods, as each excels in different aspects of performance [31] [5]. By aligning methodological selection with specific research goals and experimental designs, stem cell researchers can maximize the biological insights gained from their single-cell data.
Single-cell RNA sequencing (scRNA-seq) and single-cell proteomics have revolutionized biological research by enabling the precise classification of cell types and states, including stem cell subpopulations. scRNA-seq profiles the whole transcriptome of individual cells, offering high sensitivity and the ability to detect dynamic changes in gene expression [34]. In contrast, single-cell proteomics, particularly antibody-based technologies, quantifies protein abundance, providing direct insight into phenotypic cellular functions [5] [35]. While both modalities aim to characterize cellular heterogeneity, they exhibit fundamental differences in data distribution, feature dimensionality, and data quality that pose significant challenges for clustering algorithms [5]. These differences necessitate careful consideration when selecting computational methods for cell type identification, a critical step in research focused on stem cell subpopulation isolation and characterization.
Fundamental Data Characteristics and Technical Challenges
The inherent technological differences between transcriptomic and proteomic platforms create distinct data landscapes that clustering algorithms must navigate.
Transcriptomic Data Characteristics
- High-Dimensionality: scRNA-seq data typically captures expression levels for 20,000-25,000 genes per cell, creating an extremely high-dimensional feature space [34].
- Data Sparsity: Transcriptomic data suffers from significant "dropout" events where expressed genes fail to be detected due to low RNA capture rates, creating a zero-inflated data structure [34].
- Complex Distribution: The data exhibits over-dispersion and follows negative binomial distributions, requiring specialized statistical approaches.
Proteomic Data Characteristics
- Lower Dimensionality: Antibody-based single-cell proteomics typically measures dozens to hundreds of proteins simultaneously, resulting in a significantly lower-dimensional feature space [5].
- Denser Signals: Protein abundance measurements generally exhibit fewer dropout events and less technical noise compared to transcriptomic data [5].
- Different Scaling: Proteomic data often requires different normalization approaches as it may follow different distribution patterns than transcriptomic data.
Cross-Modality Integration Challenges
Integrating transcriptomic and proteomic data presents additional computational hurdles. The relationship between mRNA and protein levels is not linear due to post-transcriptional regulation, translation efficiency, and protein degradation [35]. This discordance means that subcellular localization information from proteomics often provides complementary rather than corroborating evidence to transcriptomic findings [35].
Table 1: Fundamental Characteristics of Transcriptomic vs. Proteomic Data
| Characteristic | Transcriptomic Data | Proteomic Data |
|---|---|---|
| Feature Dimensionality | High (20,000+ genes) | Low (tens to hundreds of proteins) |
| Data Sparsity | High dropout rate | Lower dropout rate |
| Technical Noise | Higher | Lower |
| Distribution Properties | Over-dispersed, negative binomial | Varies, often different scaling |
| Biological Interpretation | Potential activity | Functional effectors |
Benchmarking Clustering Algorithm Performance
Recent comprehensive benchmarking studies have systematically evaluated clustering algorithm performance across both omics modalities, providing empirical guidance for method selection.
Large-Scale Benchmarking Insights
A 2025 benchmark analysis evaluated 28 computational algorithms on 10 paired transcriptomic and proteomic datasets, assessing performance using Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), computational efficiency, and robustness [5] [31]. This study revealed that most clustering methods were originally designed specifically for transcriptomic data, with far fewer developed specifically for proteomic applications [5].
Top-Performing Algorithms Across Modalities
The benchmarking results identified several algorithms that demonstrate strong performance across both transcriptomic and proteomic data:
- scAIDE, scDCC, and FlowSOM consistently ranked among the top methods for both transcriptomic and proteomic data [5].
- FlowSOM additionally demonstrated excellent robustness to noise and dataset size variations [5].
- CosTaL, Seurat, and DESC have shown superior performance in specific evaluations, particularly for identifying cell subtypes and capturing cellular heterogeneity [34].
Modality-Specific Performance Variations
The study revealed significant performance variations across modalities:
- CarDEC and PARC performed well in transcriptomics (4th and 5th respectively) but dropped significantly in proteomics (16th and 18th) [5].
- Community detection-based methods generally offered a balanced trade-off between performance and computational efficiency [5].
- SC3 demonstrated strong clustering effectiveness but required more memory and exhibited slower computation speed compared to other algorithms [34].
Table 2: Top-Performing Clustering Algorithms Across Modalities
| Algorithm | Transcriptomic Performance (Rank) | Proteomic Performance (Rank) | Computational Efficiency |
|---|---|---|---|
| scAIDE | 2nd | 1st | Moderate |
| scDCC | 1st | 2nd | High (memory efficient) |
| FlowSOM | 3rd | 3rd | High (robust) |
| CarDEC | 4th | 16th | Moderate |
| PARC | 5th | 18th | Moderate |
| TSCAN/SHARP | N/A | N/A | High (time efficient) |
Experimental Protocols for Multi-Omics Clustering Validation
Robust evaluation of clustering methods requires standardized experimental protocols and validation frameworks.
Data Processing Workflows
A typical integrative analysis workflow involves:
Sample Preparation: Biological samples are processed for both transcriptomic and proteomic profiling. In stem cell research, this often involves careful isolation of subpopulations using surface markers [36].
Multi-Omics Data Generation: Simultaneous measurement of mRNA and protein expression using technologies like CITE-seq, ECCITE-seq, or Abseq [5].
Quality Control: Filtering low-quality cells and genes based on established metrics [26].
Normalization: Applying modality-specific normalization techniques to account for technical variation.
Feature Selection: Identifying highly variable genes (HVGs) for transcriptomic data and appropriate markers for proteomic data [5].
Validation Methodologies
Clustering Consistency Evaluation: Tools like scICE (Single-cell Inconsistency Clustering Estimator) assess clustering reliability by measuring inconsistency coefficients across multiple algorithm runs [26].
Multi-Run Stability Assessment: Evaluating whether clusters remain stable across different random seeds, with high inconsistency indicating unreliable results [26].
Biological Validation: Verifying identified clusters using known marker genes/proteins and functional enrichment analysis [37].
Multi-Omics Clustering Workflow: From sample preparation to biological validation.
Algorithm Selection Framework for Stem Cell Research
Selecting appropriate clustering methods requires consideration of research goals, data characteristics, and computational constraints.
Decision Framework
Algorithm Selection Guide: A decision framework for choosing clustering methods.
Performance vs. Efficiency Trade-offs
- For Top Performance Across Omics: scAIDE, scDCC, and FlowSOM are recommended, with FlowSOM offering excellent robustness [5].
- For Memory Efficiency: scDCC and scDeepCluster provide the best memory utilization [5].
- For Time Efficiency: TSCAN, SHARP, and MarkovHC offer the fastest computation times [5].
- For Rare Cell Population Identification: DESC has demonstrated promising results for cell subtype identification and capturing cellular heterogeneity [34].
Research Reagent Solutions and Computational Tools
Successful implementation of clustering analyses requires both wet-lab reagents and computational tools.
Table 3: Essential Research Reagents and Computational Tools
| Category | Item | Function/Application |
|---|---|---|
| Wet-Lab Reagents | CITE-seq Antibodies | Simultaneous measurement of surface proteins and transcriptome |
| ECCITE-seq Reagents | Expanded multimodal single-cell profiling | |
| Cell Hashing Reagents | Sample multiplexing and doublet detection | |
| Viability Staining Dyes | Exclusion of dead cells from analysis | |
| Computational Tools | Seurat | Comprehensive scRNA-seq analysis suite |
| Scanpy | Python-based single-cell analysis | |
| scICE | Clustering consistency evaluation | |
| EvaluomeR | Automated parameter optimization for clustering | |
| Benchmarking Resources | SPDB | Single-cell proteomic database with curated datasets |
| 10x Genomics Datasets | Standardized transcriptomic datasets for method validation |
The clustering of single-cell transcriptomic and proteomic data presents distinct challenges that require modality-specific considerations. Transcriptomic data's high dimensionality and sparsity demand algorithms robust to these characteristics, while proteomic data's lower dimensionality presents different analytical challenges. Benchmarking studies consistently identify scAIDE, scDCC, and FlowSOM as top-performing across both modalities, though modality-specific performance variations necessitate careful algorithm selection.
Future methodological development should focus on improved multi-omics integration techniques, enhanced scalability for increasingly large datasets, and more robust handling of technical noise. For stem cell researchers, selecting appropriate clustering methods requires balancing performance, computational efficiency, and biological question requirements. As single-cell technologies continue to evolve, so too must the computational frameworks for extracting biologically meaningful insights from these powerful datasets.
Multi-omics integration methods have become indispensable tools for researchers investigating complex biological systems, particularly in stem cell research where understanding cellular heterogeneity is crucial. The simultaneous measurement of multiple molecular layers, such as transcriptomics (RNA) and proteomics (protein abundance), provides a more comprehensive view of cellular identity and function than any single data type alone [38] [5]. Technologies like CITE-seq, ECCITE-seq, and Abseq have enabled the generation of paired transcriptomic and proteomic datasets from the same cells, creating unprecedented opportunities to explore cellular heterogeneity at multiple regulatory levels [5].
For researchers focused on stem cell subpopulation identification, selecting appropriate integration methods is critical yet challenging due to the rapid development of computational approaches. This comparison guide provides an objective evaluation of multi-omics integration methods based on recent benchmarking studies, with a specific focus on their applicability to stem cell research. We present structured performance comparisons, detailed experimental protocols, and practical recommendations to assist researchers in selecting optimal methods for their specific research contexts.
Performance Benchmarking of Integration Methods
Vertical Integration Performance
Vertical integration, which combines different omics modalities measured from the same cells, is particularly relevant for analyzing paired transcriptomic and proteomic data. Benchmarking studies have evaluated multiple methods using datasets containing paired RNA and antibody-derived tag (ADT) data representing protein abundance.
Table 1: Performance Rankings for Vertical Integration Methods (RNA+ADT)
| Rank | Method | Overall Performance | Key Strengths | Considerations for Stem Cell Research |
|---|---|---|---|---|
| 1 | Seurat WNN | Excellent | Preserves biological variation, robust across datasets | Graph-based output, no embedding |
| 2 | sciPENN | Excellent | Accurate cell type classification | Deep learning approach requires computational resources |
| 3 | Multigrate | Excellent | Effective biological signal preservation | Moderate computational demands |
| 4 | Matilda | Good | Supports feature selection for cell-type specific markers | |
| 5 | UnitedNet | Good | Consistent performance across diverse datasets | |
| 6 | scMM | Variable | Performs better on simulated data | Less effective on complex real datasets |
Source: Adapted from [38]
As shown in Table 1, Seurat WNN, sciPENN, and Multigrate demonstrate leading performance for integrating transcriptomic and proteomic data [38]. These methods effectively preserve biological variation, which is crucial for identifying subtle differences between stem cell subpopulations. Notably, method performance is both dataset-dependent and modality-dependent, highlighting the importance of selecting methods appropriate for specific data characteristics [38].
Clustering Performance on Integrated Data
After integration, clustering algorithms are applied to identify cell subpopulations. Benchmarking studies have evaluated clustering performance on integrated transcriptomic and proteomic data using metrics such as Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI).
Table 2: Clustering Method Performance on Integrated Omics Data
| Rank | Method | Transcriptomics Performance | Proteomics Performance | Integration Compatibility | Computational Efficiency |
|---|---|---|---|---|---|
| 1 | scAIDE | Top 3 | 1st | Excellent | Moderate |
| 2 | scDCC | 1st | 2nd | Excellent | High (memory efficient) |
| 3 | FlowSOM | 3rd | 3rd | Excellent | High (robust) |
| 4 | CarDEC | 4th | 16th | Variable | Moderate |
| 5 | PARC | 5th | 18th | Variable | Moderate |
Source: Adapted from [5]
Table 2 illustrates that scAIDE, scDCC, and FlowSOM demonstrate consistent top performance across both transcriptomic and proteomic modalities [5]. This cross-modal robustness makes them particularly valuable for stem cell research where both gene expression and protein abundance contribute to cellular identity. Interestingly, some methods that perform well on transcriptomic data (e.g., CarDEC, PARC) show significantly reduced performance on proteomic data, emphasizing the need for methods specifically validated on multi-omics datasets [5].
Experimental Protocols for Method Evaluation
Benchmarking Framework Design
Comprehensive benchmarking studies follow rigorous experimental protocols to ensure fair and informative comparisons of multi-omics integration methods. The general workflow encompasses data collection, preprocessing, method application, and evaluation across multiple performance dimensions.
Figure 1: Benchmarking Workflow for Multi-omics Integration Methods
Data Collection and Preprocessing
Benchmarking studies typically utilize diverse datasets representing various biological contexts and technological platforms. For transcriptomic and proteomic integration, datasets generated by CITE-seq, ECCITE-seq, and Abseq technologies are commonly used [5]. These datasets typically include:
- Gene expression matrices (RNA)
- Surface protein abundance (ADT)
- Cell type annotations (ground truth)
Data preprocessing follows standardized pipelines including quality control (filtering cells with low gene counts and genes expressed in few cells), normalization, and feature selection [39] [5]. For proteomic data, additional normalization specific to ADT counts may be applied. Studies typically select highly variable genes (HVGs) to reduce dimensionality and computational burden [5].
Evaluation Metrics and Criteria
Comprehensive benchmarking employs multiple evaluation metrics to assess different aspects of method performance:
- Clustering Accuracy: ARI, NMI, Clustering Accuracy (CA), and Purity compare identified clusters with ground truth annotations [5]
- Biological Conservation: Average silhouette width (ASW) and cell-type ASW assess how well biological variation is preserved [38]
- Batch Correction: Batch ASW and iLISI metrics evaluate effectiveness in removing technical artifacts [40]
- Runtime and Memory: Practical considerations including peak memory usage and computational time [5]
These metrics provide complementary insights into method performance, with different methods often excelling in different aspects [38].
Method Categorization and Technical Approaches
Integration Strategies
Multi-omics integration methods can be categorized based on their underlying computational approaches and integration strategies. Understanding these categories helps researchers select methods appropriate for their specific analytical needs and technical expertise.
Figure 2: Categorization of Multi-omics Integration Methods
Technical Foundations
Different methodological approaches offer distinct strengths and limitations for multi-omics integration:
Correlation/Covariance-based Methods: Canonical Correlation Analysis (CCA) and its extensions identify relationships between omics datasets by maximizing correlation. These methods are interpretable and flexible but primarily capture linear associations [41].
Matrix Factorization Methods: Approaches like Joint Matrix Factorization (JNMF) and integrative Non-negative Matrix Factorization (intNMF) decompose multiple omics datasets into shared and dataset-specific factors. These methods efficiently reduce dimensionality and identify shared molecular patterns [41] [42].
Deep Learning Methods: Variational Autoencoders (VAEs) and other neural network architectures learn complex nonlinear patterns in multi-omics data. These flexible architectures can handle missing data and perform denoising but require substantial computational resources and larger datasets [41].
Network-based Methods: Similarity Network Fusion (SNF) and related approaches construct networks representing samples for each data type then fuse these networks. These methods are robust to noise and missing data but may require extensive parameter tuning [42] [43].
The Scientist's Toolkit
Essential Research Reagents and Computational Tools
Successful multi-omics integration requires both wet-lab reagents for data generation and computational tools for analysis. The following table details key resources mentioned in benchmarking studies.
Table 3: Essential Resources for Multi-omics Integration Studies
| Resource Category | Specific Examples | Function/Purpose | Considerations for Stem Cell Research |
|---|---|---|---|
| Multi-omics Technologies | CITE-seq, ECCITE-seq, Abseq | Simultaneous measurement of transcriptome and proteome in single cells | Enables direct correlation of RNA and protein in stem cell subpopulations |
| Computational Frameworks | Seurat, Scanpy | Single-cell analysis pipelines | Provide preprocessing, normalization, and basic integration capabilities |
| Integration Methods | Seurat WNN, Multigrate, sciPENN | Integrate multiple omics modalities into unified representation | Selection should be based on data characteristics and research questions |
| Clustering Algorithms | scAIDE, scDCC, FlowSOM | Identify cell subpopulations in integrated space | Critical for discovering novel stem cell states and transitions |
| Benchmarking Platforms | iSTBench, specialized GitHub repositories | Reproducible evaluation of method performance | Facilitates method selection and experimental planning |
Source: Compiled from [38] [5] [40]
Applications in Stem Cell Research
Identifying Stem Cell Subpopulations
Multi-omics integration methods are particularly valuable in stem cell research for identifying and characterizing subpopulations with distinct functional properties. Methods capable of detecting rare cell populations, such as ProgClust and scCAD, can identify transitional states or rare stem cell subtypes that might be missed when analyzing single modalities [39] [44].
The progressive clustering approach of ProgClust, which iteratively refines clusters using population-specific genes, has demonstrated effectiveness in decomposing complex cell populations and detecting rare cells [39]. Similarly, scCAD employs cluster decomposition-based anomaly detection to identify rare cell types that may be overlooked during initial clustering phases [44]. These capabilities are particularly relevant for stem cell biology, where rare transitional states often play crucial roles in differentiation pathways and cellular identity transitions.
Considerations for Experimental Design
Benchmarking studies have revealed several important considerations for researchers planning multi-omics experiments:
Data Combination Impact: Contrary to intuition, incorporating more omics data types does not always improve results and may sometimes negatively impact performance [43]. Careful selection of relevant omics layers is essential.
Method Selection: No single method consistently outperforms others across all datasets and tasks [38] [40]. Method performance depends on application context, dataset size, and technology [40].
Computational Resources: Deep learning methods like sciPENN and scAIDE often require significant computational resources, which may constrain their application to very large datasets [38] [5].
Scalability: Methods exhibit different scalability characteristics, with some (e.g., FlowSOM, scDCC) demonstrating better performance on large datasets [5].
Multi-omics integration methods for combining transcriptomic and proteomic data have matured significantly, with several approaches (Seurat WNN, sciPENN, Multigrate for integration; scAIDE, scDCC, FlowSOM for clustering) demonstrating consistently strong performance across benchmarking studies. For stem cell researchers focused on subpopulation identification, selection of appropriate methods should consider specific data characteristics, analytical priorities, and available computational resources.
The rapid evolution of multi-omics technologies and computational methods continues to enhance our ability to resolve cellular heterogeneity. Future developments will likely focus on improved scalability, handling of missing data, and incorporation of spatial information, further advancing stem cell research and therapeutic development.
In stem cell research, the precise identification of distinct cell subpopulations—such as pluripotent stem cells, progenitors, and differentiated cells—is fundamental to understanding developmental biology and developing regenerative therapies. Single-cell RNA sequencing (scRNA-seq) technology has revolutionized this field by enabling the measurement of gene expression in individual cells, thereby revealing cellular heterogeneity from a single-cell perspective [45]. Cluster analysis serves as a critical initial step in this process, aiming to group cells based on the similarity of their gene expression profiles. The primary goal is to maximize the similarity among cells within the same cluster while minimizing dissimilarity between different clusters, which allows researchers to identify new cell types, predict cell developmental trajectories, and reconstruct spatial models of complex tissues [45]. This guide provides a structured workflow from raw data to cluster assignment, framed within the context of benchmarking clustering algorithms, to aid researchers in selecting and implementing the most appropriate methods for their specific experimental needs.
Experimental Workflow: From Raw Data to Clusters
The journey from raw sequencing data to biologically meaningful cluster assignments is a multi-stage process. Each stage requires careful execution to ensure the final results are robust and interpretable.
Figure 1: A Comprehensive Workflow for Cluster Analysis in Single-Cell Data. This diagram outlines the key stages from raw data processing to biological interpretation.
Data Preprocessing and Cleaning
The initial phase focuses on converting raw sequencing data into a high-quality gene expression matrix suitable for analysis.
- Data Cleaning and Imputation: scRNA-seq data is notoriously susceptible to technical noise, including low mRNA capture efficiency and environmental perturbations, resulting in high-dimensional, sparse data with excess zeros [45]. Most clustering algorithms cannot handle missing values, necessitating a strategy for their treatment. Common approaches include complete case analysis (removing cells with missing data), replacing missing values with the variable's mean, or more sophisticated imputation methods like k-nearest neighbor imputation, which uses the values from the most similar cells to estimate missing values [46].
- Normalization and Scaling: Normalization is critical to adjust for varying sequencing depths across cells, ensuring that expression levels are comparable. Following normalization, feature scaling standardizes the range of features, preventing variables with inherently larger scales (e.g., highly expressed genes) from dominating the clustering process. Techniques like min-max scaling (rescaling to a [0, 1] range) or z-score scaling (standardizing to a mean of 0 and variance of 1) are commonly employed [47] [48]. This step is particularly important for algorithms like K-means and those involving gradient descent, as it leads to faster convergence and more stable results [49].
- Selection of Highly Variable Genes (HVGs): To reduce noise and computational burden, the dataset is typically filtered to include only HVGs, which are genes that show high cell-to-cell variation. These genes are most likely to represent biologically interesting differences between cell types rather than technical noise. The impact of HVG selection on downstream clustering performance is a key consideration during benchmarking [5].
Feature Engineering and Dimensionality Reduction
Following preprocessing, feature engineering transforms the data to make clustering more effective.
- Dimensionality Reduction: The gene expression matrix is high-dimensional, often containing measurements for thousands of genes. Clustering algorithms can struggle with this "curse of dimensionality" [50]. Dimensionality reduction techniques project the data into a lower-dimensional space while preserving its essential structure.
- Principal Component Analysis (PCA): A linear technique that transforms the data into a set of linearly uncorrelated principal components, ordered by the amount of variance they explain from the original data [49]. It is widely used as an initial step before clustering.
- t-SNE and UMAP: Non-linear techniques particularly well-suited for visualization in 2D or 3D. They are powerful for revealing complex, non-linear relationships and cluster structures in the data [50] [46].
- Feature Extraction and Selection: This process involves creating new features or selecting a subset of the most relevant ones. Feature extraction methods like PCA create new, surrogate variables (principal components), while feature selection involves choosing an informative subset of the original genes [48]. This reduces noise and improves the computational efficiency and quality of the clustering results [46].
Clustering Algorithm Application
The core of the workflow involves applying a clustering algorithm to the processed data. Benchmarking studies systematically evaluate numerous algorithms to guide selection.
- Algorithm Selection: The choice of algorithm depends on the data characteristics and the biological question. As illustrated in the benchmarking results below, algorithms exhibit different strengths. For instance, some are optimized for transcriptomic data, while others show robust performance across both transcriptomic and proteomic data [5].
- Parameter Tuning: Most clustering algorithms require user-defined parameters, such as the number of clusters (k) in K-means or the resolution parameter in graph-based methods. Determining the optimal parameters is an iterative process that can be informed by statistical measures (e.g., the silhouette score) and biological plausibility.
Benchmarking Clustering Algorithms: A 2025 Perspective
A comprehensive benchmark study published in Genome Biology (2025) evaluated 28 computational algorithms on 10 paired transcriptomic and proteomic datasets [5]. The performance was assessed using multiple metrics, including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), clustering accuracy, purity, peak memory usage, and running time. This provides a robust, data-driven foundation for algorithm selection.
Table 1: Top-Performing Clustering Algorithms Across Single-Cell Omics Data (2025 Benchmark)
| Algorithm | Overall Ranking (Transcriptomics) | Overall Ranking (Proteomics) | Key Strengths | Computational Profile |
|---|---|---|---|---|
| scAIDE | 2 | 1 | High generalizability across omics | Balanced performance |
| scDCC | 1 | 2 | Top accuracy in transcriptomics; Memory efficient | Memory efficient |
| FlowSOM | 3 | 3 | Excellent robustness; Fast | Time efficient; Robust |
| TSCAN | N/A | N/A | High time efficiency | Very time efficient |
| SHARP | N/A | N/A | High time efficiency | Very time efficient |
| scDeepCluster | N/A | N/A | Good memory efficiency | Memory efficient |
The benchmark revealed that scAIDE, scDCC, and FlowSOM consistently delivered top-tier performance across both transcriptomic and proteomic data modalities, suggesting strong generalization capabilities [5]. For users with specific computational constraints, the study provided further recommendations: scDCC and scDeepCluster are recommended for memory-efficient analysis, while TSCAN, SHARP, and MarkovHC are ideal for scenarios where time efficiency is a priority [5].
Impact of Data Modality and Granularity
Table 2: Algorithm Performance Sensitivity to Data Characteristics
| Algorithm | Performance on Transcriptomics | Performance on Proteomics | Notes on Cell Type Granularity |
|---|---|---|---|
| scDCC | Best (Rank 1) | Excellent (Rank 2) | Robust across granularities |
| scAIDE | Excellent (Rank 2) | Best (Rank 1) | Robust across granularities |
| CarDEC | Good (Rank 4) | Moderate (Rank 16) | Performance drops significantly on proteomics |
| PARC | Good (Rank 5) | Moderate (Rank 18) | Performance drops significantly on proteomics |
A key finding was that algorithm performance can be highly modality-specific. Some methods, like CarDEC and PARC, which ranked 4th and 5th in transcriptomics, respectively, saw their rankings drop significantly (to 16th and 18th) when applied to proteomic data [5]. This underscores the importance of selecting an algorithm benchmarked on the specific data type in use. Furthermore, the robustness of these methods was tested using 30 simulated datasets, with FlowSOM emerging as a particularly robust option [5]. The study also noted that cell type granularity—the level of detail at which cell subtypes are defined—impacts clustering performance, making it a critical factor during method selection and result interpretation [5].
The Scientist's Toolkit: Essential Research Reagents and Materials
Successful execution of the clustering workflow relies on both computational tools and wet-lab reagents. The following table details key solutions used in the generation and analysis of single-cell data cited in benchmark studies.
Table 3: Key Research Reagent Solutions for Single-Cell Omics Studies
| Reagent / Solution | Function in Workflow | Application Context |
|---|---|---|
| CITE-seq Reagents | Simultaneous quantification of mRNA and surface protein levels in individual cells using oligonucleotide-labeled antibodies. | Paired transcriptomic and proteomic data generation [5]. |
| ECCITE-seq Reagents | An expanded version of CITE-seq that allows for the capture of multiple modalities from single cells. | Paired multi-omics data generation [5]. |
| Abseq Reagents | Utilizes DNA-barcoded antibodies for high-throughput single-cell proteomic measurements. | Single-cell proteomic data generation [5]. |
| Chromium Single Cell 3' / 5' Reagent Kits (10x Genomics) | Provides a robust workflow for partitioning cells into nanoliter-scale droplets for single-cell RNA sequencing. | Widely used for scRNA-seq library preparation. |
| Seurat v3 | A comprehensive R toolkit for single-cell genomics, encompassing preprocessing, normalization, dimensionality reduction, clustering, and differential expression. | Data preprocessing, clustering, and analysis [5]. |
Detailed Experimental Protocols
To ensure reproducibility and facilitate the adoption of these methods, below are detailed protocols for key experiments and analyses cited in the benchmark studies.
Protocol: Benchmarking Clustering Algorithms
This protocol is adapted from the large-scale benchmark study [5].
- Dataset Curation: Obtain 10 real paired single-cell transcriptomic and proteomic datasets from public repositories like SPDB and Seurat v3. These should span at least 5 tissue types, encompass over 50 cell types, and include more than 300,000 cells. Datasets should be generated with multi-omics technologies (CITE-seq, ECCITE-seq, Abseq).
- Algorithm Selection and Setup: Select a diverse set of 28 clustering algorithms, including classical machine learning-based methods (e.g., SC3, CIDR), community detection-based methods (e.g., Leiden, Louvain), and deep learning-based methods (e.g., scDCC, scAIDE).
- Data Preprocessing: For each dataset, apply a standardized preprocessing pipeline. This includes quality control (removing low-quality cells and genes), normalization (e.g., log-normalization), and scaling. The selection of Highly Variable Genes (HVGs) should be documented and consistent.
- Clustering Execution: Run each clustering algorithm on both the transcriptomic and proteomic components of every dataset. Use default parameters as recommended by the original authors or perform a standardized parameter search.
- Performance Evaluation:
- Calculate external metrics like Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI) by comparing cluster assignments to ground truth cell type labels.
- Record computational metrics: Peak Memory Usage (in GB) and Running Time (in seconds or minutes).
- Robustness Assessment: Evaluate robustness by applying the algorithms to 30 simulated datasets with varying noise levels and dataset sizes.
- Integrated Data Analysis: Use 7 state-of-the-art integration methods (e.g., moETM, totalVI) to fuse the paired transcriptomic and proteomic data. Re-run the single-omics clustering algorithms on these integrated features and evaluate their performance.
Protocol: Standardized K-means Clustering
As a widely used method, the K-means protocol is detailed below [46].
- Specify the Number of Clusters (k): Define the number of clusters, k. Since the optimal k is often unknown, this process is typically repeated for a range of k values.
- Initialize Cluster Centroids: Randomly select k data points from the dataset to serve as the initial cluster centroids.
- Assign Objects to Clusters: Calculate the Euclidean distance from each data point to every cluster centroid. Assign each data point to the cluster whose centroid is the closest.
- Compute New Cluster Means: For each newly formed cluster, compute the mean (centroid) of all data points assigned to it.
- Iterate Until Convergence: Repeat steps 3 and 4, reassigning data points and recalculating centroids, until the cluster assignments no longer change (or change minimally), indicating the solution has converged.
The journey from raw single-cell data to confident cluster assignment is a structured process involving meticulous preprocessing, thoughtful feature engineering, and the application of a suitably benchmarked clustering algorithm. The recent comprehensive benchmark highlights that while no single algorithm is universally superior, informed choices can be made based on data modality and computational needs. Methods like scAIDE, scDCC, and FlowSOM have demonstrated leading performance and robustness across diverse data types. By adhering to the detailed workflow and protocols outlined in this guide, researchers in stem cell biology and drug development can more reliably identify and characterize cell subpopulations, thereby accelerating discoveries in regenerative medicine and therapeutic development.
Overcoming Common Challenges: Parameter Tuning, Noise Handling, and Computational Efficiency
In stem cell research, accurately identifying distinct subpopulations—such as progenitor cells, differentiated states, and transitional cell types—is fundamental to understanding developmental pathways and disease mechanisms. Single-cell RNA sequencing (scRNA-seq) has revolutionized this field by enabling researchers to profile transcriptomes at unprecedented resolution. Clustering analysis serves as the computational cornerstone for interpreting these complex datasets, transforming high-dimensional gene expression matrices into biologically meaningful cell groups. While the Elbow Method has long been a standard technique for determining optimal cluster numbers in K-means clustering, its subjective nature and limitations with complex biological data have driven the development of more sophisticated validation approaches [51] [52].
The challenge of selecting appropriate cluster numbers is particularly pronounced in stem cell biology, where cellular heterogeneity exists along continuous differentiation trajectories rather than discrete partitions. Under-clustering can obscure biologically distinct cell states, while over-clustering can create artificial subdivisions that misrepresent the underlying biology. This comparative guide evaluates advanced cluster validation techniques through the lens of rigorous benchmarking studies, providing stem cell researchers with evidence-based recommendations for robust subpopulation identification in scRNA-seq data analysis.
Beyond the Elbow: Advanced Cluster Validation Techniques
The Elbow Method's primary limitation lies in its reliance on visual interpretation of the "elbow point" in the within-cluster sum of squares (WCSS) curve, introducing subjectivity and inconsistency, especially with complex, high-dimensional biological data where clear elbows may not exist [51] [52] [53]. Fortunately, several more robust statistical approaches have been developed that offer quantitative frameworks for determining optimal cluster numbers.
Quantitative Validation Metrics
Silhouette Coefficient: This metric measures how similar each cell is to its own cluster compared to other clusters, producing scores between -1 and 1. Higher average silhouette widths indicate better-defined clusters. The optimal cluster number corresponds to the value that maximizes this score [52] [53].
Calinski-Harabasz Index: Also known as the variance ratio criterion, this index evaluates cluster quality by calculating the ratio between between-cluster dispersion and within-cluster dispersion. Higher values indicate better cluster separation, with the maximum value suggesting the optimal number [52].
Davies-Bouldin Index: This measure computes the average similarity between each cluster and its most similar counterpart, with lower values indicating better cluster separation. Its robustness to noise makes it particularly suitable for scRNA-seq data containing technical variability [54] [52].
Gap Statistic: This approach compares the total within-cluster variation from the actual data to the expected variation under an appropriate null reference distribution. The cluster number that maximizes the gap statistic represents the optimal value, making it effective for higher-dimensional data [52].
Table 1: Comparison of Cluster Validation Metrics
| Metric | Optimal Value | Strengths | Limitations | Suitable Data Types |
|---|---|---|---|---|
| Silhouette Coefficient | Maximum | Intuitive interpretation; scales from -1 to 1 | Computationally intensive for large datasets | Medium-sized datasets with clear separation |
| Calinski-Harabasz Index | Maximum | Fast computation; no assumption of convex clusters | Biased toward similar-sized clusters | Datasets with spherical clusters |
| Davies-Bouldin Index | Minimum | Robust to noise; simple calculation | Tendency to decrease as clusters increase | Noisy datasets with irregular shapes |
| Gap Statistic | Maximum | Reference distribution accounts for random chance; works well in high dimensions | Sensitive to choice of reference distribution | High-dimensional data like scRNA-seq |
| Bayesian Information Criterion (BIC) | Minimum | Formal probabilistic foundation; penalizes complexity | Assumes specific data distribution | Datasets where distributional assumptions hold |
Automated Solutions for Cluster Number Determination
For researchers seeking to minimize manual intervention, automated approaches can determine optimal cluster numbers directly from data. The n_clusters() function from the parameters package in R implements 27 different clustering methods, including the highly accurate Hartigan and Tracew methods, which demonstrated 100% accuracy in identifying correct cluster numbers across simulated and real datasets [55]. These automated approaches are particularly valuable for standardized analytical pipelines where consistency and reproducibility are paramount.
Benchmarking Clustering Algorithms for Single-Cell Data
Recent comprehensive benchmarking studies have systematically evaluated clustering performance specifically for transcriptomic data, providing evidence-based guidance for method selection in stem cell research.
Performance Evaluation Across scRNA-seq Datasets
A 2025 benchmark study published in Genome Biology evaluated 28 clustering algorithms on 10 paired transcriptomic and proteomic datasets, assessing performance using Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), computational efficiency, and robustness [5] [31]. The top-performing methods for transcriptomic data included scAIDE, scDCC, and FlowSOM, which demonstrated strong performance and generalization across different omics modalities [5]. These methods outperformed traditional approaches in accurately identifying cell populations while maintaining computational efficiency.
Table 2: Top-Performing scRNA-seq Clustering Algorithms Based on Benchmark Studies
| Algorithm | ARI Score | NMI Score | Computational Efficiency | Key Strengths | Best Suited for |
|---|---|---|---|---|---|
| scAIDE | High (Ranked 1st for proteomics) | High | Moderate | Top cross-omics performance; excellent generalization | Studies requiring high accuracy across modalities |
| scDCC | High (Ranked 1st for transcriptomics) | High | High (recommended for memory efficiency) | Deep learning approach; handles high dimensionality | Large-scale datasets with complex structures |
| FlowSOM | High (Ranked 3rd for both omics) | High | High (excellent robustness) | Fast execution; handles large cell numbers | Large datasets requiring rapid processing |
| SHARP | Moderate | Moderate | High (recommended for time efficiency) | Scalable to massive datasets; ensemble approach | Extremely large datasets (>1 million cells) |
| scICE | N/A | N/A | High (30× faster than consensus methods) | Quantifies clustering consistency; reduces stochastic effects | Assessing reliability of clustering results |
Ensemble Methods for Enhanced Robustness
Ensemble clustering approaches address methodological bias by integrating results from multiple clustering methods. The scEVE algorithm represents an advanced ensemble approach that applies multiple clustering methods (including monocle3, Seurat, densityCut, and SHARP) to generate "base clusters," then identifies "robust clusters" through pairwise similarity metrics [56]. Unlike conventional ensemble methods that minimize differences between clustering results, scEVE describes these differences to identify clusters robust to methodological variations while quantifying their uncertainty—particularly valuable for identifying rare stem cell subpopulations where consistency across methods increases confidence in biological validity [56].
Experimental Protocols for Cluster Validation Benchmarking
To ensure reproducibility and facilitate implementation in stem cell research workflows, this section outlines detailed methodologies from key benchmarking studies cited in this guide.
Benchmarking Framework for scRNA-seq Clustering
The comprehensive benchmarking protocol employed in the Genome Biology 2025 study provides a robust experimental framework suitable for evaluating clustering performance in stem cell datasets [5] [31]:
Dataset Selection and Preprocessing: Utilize 10 paired transcriptomic and proteomic datasets encompassing diverse tissue types and over 50 cell types. Implement standard quality control including filtering of low-quality cells and genes, normalization, and log-transformation.
Feature Selection: Select highly variable genes (HVGs) using the
FindVariableFeatures()function from the Seurat package, typically setting the number to 1,000-2,000 genes to balance biological signal and computational efficiency.Algorithm Evaluation: Apply 28 clustering algorithms with default parameters to ensure fair comparison. For stochastic methods, perform multiple runs with different random seeds.
Performance Assessment: Calculate evaluation metrics including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), clustering accuracy, and purity by comparing computational clusters to established biological labels.
Efficiency Analysis: Measure peak memory usage and running time for each method under standardized conditions.
Robustness Evaluation: Test methods on 30 simulated datasets with varying noise levels and dataset sizes to assess performance under different technical conditions.
Ensemble Clustering with scEVE
The scEVE algorithm employs the following workflow to generate robust clusters [56]:
Input Processing: Begin with a single-cell count matrix, select 1,000 highly variable genes using
FindVariableFeatures(), and use their expression to generate base clusters.Base Cluster Generation: Apply multiple clustering methods (monocle3, Seurat, densityCut, and SHARP) with default parameters. For densityCut, transform count data to log2(TPM) using the
calculateTPM()function from the scater package.Similarity Calculation: Compute pairwise similarity between base clusters using the formula Sx,y = min(Nx∩y/Nx, Nx∩y/Ny), where Nx∩y represents the number of cells in both clusters x and y, and Nx represents cells in cluster x.
Robust Cluster Identification: Identify strong pairwise similarities exceeding a threshold (Slim = 0.5) to detect clusters consistently identified across multiple methods.
Biological Validation: Apply a filter based on marker genes to ensure robust clusters are biologically distinct and informative for downstream analysis.
Clustering Consistency Evaluation with scICE
The scICE framework addresses clustering inconsistency through the following protocol [26]:
Quality Control: Filter low-quality cells and genes using standard thresholds (mitochondrial percentage < 10%, feature counts between 200-2,500).
Dimensionality Reduction: Apply scLENS dimensionality reduction method for automatic signal selection to reduce data size while preserving biological variation.
Graph Construction: Build a shared nearest neighbor graph based on distances between cells in the reduced space.
Parallel Clustering: Distribute the graph to multiple processes running across cores, applying the Leiden algorithm simultaneously with different random seeds.
Inconsistency Calculation: Compute the Inconsistency Coefficient (IC) using element-centric similarity to quantify clustering stability without constructing computationally expensive consensus matrices.
Reliable Cluster Identification: Identify clustering resolutions with IC close to 1, indicating high consistency across random seeds.
Visualization of Clustering Workflows
scEVE Ensemble Clustering Algorithm
Cluster Validation Methodology
The Scientist's Toolkit: Essential Research Reagents and Computational Solutions
Table 3: Essential Computational Tools for scRNA-seq Cluster Analysis
| Tool/Resource | Function | Application Context | Implementation |
|---|---|---|---|
| Seurat | scRNA-seq analysis toolkit | Data preprocessing, integration, and basic clustering | R package: FindVariableFeatures() for HVG selection |
| scater | Single-cell analysis | Data transformation and quality control | R package: calculateTPM() for TPM transformation |
| parameters package | Optimal cluster determination | Automated K selection using 27 methods | R package: n_clusters() function |
| Scikit-learn | General machine learning | Implementation of K-means and validation metrics | Python library: silhouettescore, calinskiharabasz_score |
| Scanpy | Single-cell analysis | End-to-end scRNA-seq processing and clustering | Python package: PP, TL, and PL modules |
| Highly Variable Genes | Feature selection | Reducing dimensionality while preserving biological signal | Typically 1,000-2,000 genes selected by variance |
| Adjusted Rand Index | Validation metric | Comparing computational clusters to biological labels | Values closer to 1 indicate better agreement |
| Inconsistency Coefficient | Clustering stability | Assessing reliability across algorithm iterations | IC close to 1 indicates high consistency |
Determining optimal cluster numbers in scRNA-seq data extends far beyond the traditional Elbow Method, with modern approaches leveraging statistical rigor and computational sophistication to enhance biological discovery. For stem cell researchers investigating cellular heterogeneity, the integration of multiple validation metrics—particularly the Silhouette Coefficient and Davies-Bouldin Index—provides a more robust framework for identifying genuine biological subpopulations versus technical artifacts.
The benchmarking evidence consistently identifies scAIDE, scDCC, and FlowSOM as top-performing clustering algorithms for transcriptomic data, each offering distinct advantages in accuracy, computational efficiency, and robustness. Ensemble methods like scEVE and consistency evaluation tools like scICE further strengthen analytical pipelines by quantifying uncertainty and reducing methodological bias. By adopting these advanced cluster validation techniques and leveraging continuously updated benchmarking resources, stem cell researchers can navigate the complexities of single-cell data with greater confidence, ultimately accelerating discoveries in developmental biology, regenerative medicine, and therapeutic development.
Technical variability, including batch effects, dropouts, and normalization artifacts, presents significant challenges in single-cell RNA sequencing (scRNA-seq) studies aimed at identifying stem cell subpopulations. These technical confounders can obscure true biological signals, leading to misinterpretation of cellular heterogeneity and inaccurate identification of rare cell populations. As stem cell research progresses toward clinical applications, robust benchmarking of computational methods for handling technical variability becomes paramount. This guide provides an objective comparison of methodologies and tools designed to mitigate these technical challenges, synthesizing performance data from controlled benchmark experiments to inform selection of optimal analytical approaches for stem cell research and drug development.
Comprehensive Comparison of Normalization and Batch Effect Correction Methods
Performance Evaluation Across Experimental Setups
Table 1: Comparative Performance of Normalization Methods for Microbiome Data (Relevant to Compositional scRNA-seq Data)
| Method Category | Specific Methods | Performance Strengths | Performance Limitations | OptUse Cases |
|---|---|---|---|---|
| Scaling Methods | TMM, RLE | Consistent performance across conditions; TMM maintains AUC >0.6 with population effects <0.2 [57] | Performance declines with increasing population effects; RLE may misclassify controls as cases [57] | General purpose normalization with moderate batch effects |
| Transformation Methods | Blom, NPN, STD | Effectively align data distributions across populations; handle skewed distributions and extreme values [57] | CLR and VST performance decreases with increasing population effects [57] | Heterogeneous populations with diverse background distributions |
| Batch Correction Methods | BMC, Limma, cytoNorm, cyCombine, ComBat-ref | Consistently outperform other approaches; maintain high AUC, accuracy, sensitivity, and specificity [57] [58] [59] | QN may distort true biological variation by forcing identical distributions [57] | Multi-batch experiments with significant technical variability |
| Prior Knowledge Methods | scmap-cell, scmap-cluster, scPred | Effective for within-dataset predictions; incorporate cell type marker information [60] | Performance decreases with deeply annotated datasets (many cell populations) [60] | Well-annotated reference datasets with established markers |
Table 2: Performance Metrics for Automatic Cell Identification Methods in scRNA-seq Data
| Method Type | Representative Methods | Median F1-Score (Pancreatic Datasets) | Unlabeled Cells (%) | Computation Time | Performance with Deep Annotations |
|---|---|---|---|---|---|
| General Purpose Classifiers | SVM, SVMrejection | 0.980-0.991 [60] | 0-1.5% [60] | Moderate | Maintains high performance (F1-score >0.96) [60] |
| Single-Cell Specific | scmap-cell, scmap-cluster, scPred | 0.981-0.984 [60] | 4.2-10.8% [60] | Fast to Moderate | Performance decreases with more populations (9.5-17.7% unlabeled) [60] |
| Deep Learning Methods | Cell-BLAST, scVI | Variable across datasets [60] | Not specified | Longer training time | Low performance on deeply annotated datasets (AMB92, TM) [60] |
| Network-Based Methods | PACSI | AUC: 0.96, AUPR: 0.99 on simulated data [61] | Not applicable | Computationally intensive | Effective for phenotype-associated subpopulation identification [61] |
Experimental Protocols for Method Evaluation
Intra-dataset vs. Inter-dataset Validation Frameworks
The performance of normalization and batch correction methods must be evaluated under different experimental setups that reflect real-world research scenarios [60]:
Intra-dataset Validation: Applying 5-fold cross-validation within each dataset provides an ideal scenario to evaluate specific aspects of classification performance (e.g., feature selection, scalability across different annotation levels) without the confounding effects of technical variations across datasets. This approach is valuable for establishing baseline performance but may overestimate real-world applicability [60].
Inter-dataset Validation: A more realistic and practical evaluation where a reference dataset (e.g., stem cell atlas) is used to train a classifier, which is then applied to identify cells in new unannotated datasets. This setup directly tests method robustness to technical variability between different experiments, sequencing platforms, and laboratory conditions [60].
Controlled Benchmark Experiment Design
Proper benchmarking requires specifically designed experiments with known ground truth. The following protocol outlines a comprehensive approach for evaluating methods handling technical variability:
Experimental Workflow for scRNA-seq Method Benchmarking
Figure 1: Benchmarking workflow for evaluating computational methods using controlled cell line mixtures.
Cell Line Selection: Utilize multiple characterized cell lines with known genetic profiles. For example, the lung cancer cell line benchmark incorporates seven unique lines (PC9/EGFR, A549/KRAS, NCI-H1395/BRAF, DV90/ERBB2, NCI-H596/MET, HCC78/ROS1, CCL-185-IG/ALK) representing distinct driver mutations with partially overlapping functional pathways [62].
Controlled Mixing: Combine cells from different lines in varying proportions to simulate the heterogeneity found in real biological samples while maintaining ground truth. This enables quantitative assessment of method sensitivity in detecting rare subpopulations [62].
scRNA-seq Processing: Process samples using standard platforms (e.g., 10X Genomics Chromium Next GEM Single Cell 3' Kit) with consistent library preparation protocols. Include technical replicates across different batches to introduce controlled batch effects [62].
Data Generation: Generate count matrices using standardized processing pipelines (e.g., Cell Ranger with intronic reads included in quantification). Implement sample multiplexing using barcode oligonucleotides to enable demultiplexing during count table generation [62].
Method Application: Apply normalization, imputation, and batch correction methods to the generated data. For classification methods, utilize both intra-dataset and inter-dataset validation frameworks [60].
Performance Assessment: Quantify method performance using multiple metrics including accuracy, F1-score, percentage of unclassified cells, area under the receiver operating characteristic curve (AUC), area under the precision-recall curve (AUPR), and computation time [60] [61].
Advanced Methods for Specific Technical Challenges
Network-Based Approaches for Phenotype Association
Methods like PACSI (Phenotype-Associated Cell Subpopulation Identification) address the critical challenge of linking cellular subpopulations to disease phenotypes despite technical variability. The approach leverages biological networks to enhance interpretability and performance [61]:
Network-Based Method Workflow
Figure 2: Network-based workflow for identifying phenotype-associated cell subpopulations.
Signature Extraction: Identify highly expressed genes for each cell and bulk sample relative to others in the dataset. The size of signature genes (typically 50-250 genes) significantly influences performance, with 150 genes demonstrating optimal performance in simulated data [61].
Network-Based Proximity Calculation: Map signature genes to protein-protein interaction networks and compute the average shortest path length between cell and sample modules. This proximity quantifies correlation between cells and phenotype of interest while accounting for biological relationships beyond direct gene expression [61].
Significance Assessment: Compare observed proximity measures to a reference distribution generated by randomly assigning genes in cell signatures. This statistical framework identifies significantly associated cells while controlling for false discoveries [61].
Rare Cell Population Identification
The identification of rare cell types, particularly relevant in stem cell research for detecting progenitor populations, requires specialized approaches. Methods like scSID (single-cell Similarity Division algorithm) address this challenge by analyzing both inter-cluster and intra-cluster similarities to identify rare populations based on similarity differences [63]. These methods demonstrate exceptional scalability and ability to identify rare cell populations in complex datasets such as 68K PBMC and intestinal epithelium [63].
Table 3: Key Research Reagent Solutions for scRNA-seq Benchmarking Studies
| Resource Type | Specific Examples | Application Context | Performance Characteristics |
|---|---|---|---|
| Reference Cell Lines | PC9 (EGFR), A549 (KRAS), NCI-H1395 (BRAF), DV90 (ERBB2), NCI-H596 (MET), HCC78 (ROS1), CCL-185-IG (ALK) [62] | Controlled benchmark experiments for evaluating method performance | Each line possesses specific driver mutations with partially overlapping pathways enabling controlled heterogeneity studies |
| scRNA-seq Platforms | 10X Genomics Chromium Next GEM Single Cell 3' Kit [62] | Standardized single-cell processing | Enables consistent library preparation with sample multiplexing capabilities |
| Cell Multiplexing Reagents | Cell-Plex Oligos (10X Genomics) [62] | Sample multiplexing in scRNA-seq experiments | Allows combination of up to 12 samples with integrated demultiplexing in count table generation |
| Protein-Protein Interaction Databases | MINT Database (69,567 human PPIs) [61] | Network-based analysis methods | Provides comprehensive interaction data; largest connected component retains >99% of edges |
| Computational Frameworks | SVM, Scissor, DEGAS, PACSI [60] [61] | Cell type identification and phenotype association | Variable performance across datasets; SVM shows consistent performance in benchmarking |
| Benchmarking Datasets | Lung cancer cell line mixtures, Allen Mouse Brain, Tabula Muris, Pancreatic cell datasets [60] [62] | Method validation and comparison | Provide ground truth for algorithm evaluation across different complexity levels |
Technical variability in scRNA-seq data presents significant challenges for stem cell subpopulation identification, but rigorous benchmarking enables selection of optimal methodological strategies. Based on comprehensive performance comparisons, researchers should consider batch correction methods like BMC, Limma, or ComBat-ref when working with multi-batch experiments, while transformation methods such as Blom and NPN show promise for heterogeneous populations. General-purpose classifiers like SVM demonstrate consistent performance across diverse datasets, while network-based approaches like PACSI offer enhanced biological interpretability for phenotype association studies. Controlled benchmark experiments utilizing well-characterized cell line mixtures provide the most reliable framework for method evaluation, enabling objective comparison and guiding selection of optimal computational approaches for specific research contexts in stem cell biology and drug development.
High-dimensional data from single-cell RNA sequencing (scRNA-seq) and other single-cell omics technologies have revolutionized stem cell research, enabling the precise identification of novel subpopulations and cell states. However, the "curse of dimensionality" presents significant analytical challenges, including increased computational complexity, noise amplification, and the risk of overfitting. Effectively addressing these challenges through feature selection and dimensionality reduction (DR) is a critical prerequisite for successful clustering and biological interpretation. This guide provides a comprehensive, evidence-based comparison of current methodologies, benchmarking their performance for the specific analytical task of stem cell subpopulation identification. By synthesizing findings from large-scale benchmark studies, we offer stem cell researchers actionable insights for selecting and implementing optimal computational approaches tailored to their experimental goals and data characteristics.
Benchmarking Feature Selection Methods
The Impact of Feature Selection on Downstream Analysis
Feature selection (FS) is a crucial preprocessing step that identifies the most informative genes or features, thereby reducing noise, computational load, and the risk of overfitting. Recent benchmarking demonstrates that FS profoundly affects the quality of subsequent data integration and clustering, which are essential for discerning stem cell subpopulations. A 2025 registered report in Nature Methods systematically evaluated over 20 FS methods, revealing that the choice of FS strategy significantly impacts batch effect correction, biological variation preservation, and the accuracy of query cell mapping to reference atlases [64].
The study established that Highly Variable Gene (HVG) selection remains the most effective and widely adopted practice for producing high-quality integrations. However, it also highlighted that the number of selected features, the use of batch-aware selection protocols, and the interaction between FS methods and integration models are critical factors often overlooked in standard analytical workflows [64]. For stem cell researchers building or using reference atlases, these factors determine the ability to conservatively map new query samples and identify rare or unseen cell populations, such as novel progenitor states.
Comparative Performance of Feature Selection Strategies
Table 1: Benchmarking of Feature Selection Methods for Single-Cell Data
| Feature Selection Method | Primary Category | Key Strengths | Limitations & Considerations |
|---|---|---|---|
| Highly Variable Genes (HVG) [64] | Filter | Effective for general use; preserves biological variation; fast computation. | Performance can be dataset-specific; may require tuning of the number of genes. |
| Batch-Aware HVG [64] | Filter | Superior for integrating data across multiple batches or technologies. | More complex implementation; requires batch information. |
| Random Selection [64] | Baseline | Serves as a negative control in benchmarks. | Not recommended for analytical use; leads to poor integration quality. |
| Stably Expressed Genes [64] | Filter | Serves as a negative control; useful for testing specificity. | Not recommended for identifying variable cell types. |
| Wrapper & Embedded Methods [65] | Wrapper/Embedded | Can yield highly optimized feature sets for specific classifiers. | High computational cost; risk of overfitting to the training data. |
For analytical tasks beyond integration, such as direct classification, hybrid and embedded FS methods show notable promise. A 2025 benchmark evaluating hybrid algorithms like TMGWO (Two-phase Mutation Grey Wolf Optimization) for medical diagnostics demonstrated that such approaches can achieve high accuracy (>96%) with a minimal number of features, significantly reducing model complexity [65]. Similarly, in industrial fault diagnostics, embedded methods like Random Forest Importance (RFI) and Recursive Feature Elimination (RFE) were shown to be highly effective at selecting a compact set of informative features from time-series data, boosting classification performance while maintaining interpretability [66].
Benchmarking Dimensionality Reduction Techniques
A Comparative Framework for DR Performance
Dimensionality reduction projects high-dimensional data into a lower-dimensional space suitable for visualization and clustering. The performance of DR methods is highly context-dependent, varying with data type and analytical objective.
Table 2: Benchmarking of Dimensionality Reduction Methods for Biological Data
| DR Method | Category | Preservation Focus | Performance in Transcriptomic Benchmarks | Computational Notes |
|---|---|---|---|---|
| PCA [67] [68] | Linear | Global variance | Poor at separating distinct biological responses [68]. | Fast, interpretable, good baseline. |
| t-SNE [68] | Nonlinear | Local neighborhoods | Top-tier in clustering drug responses & MOAs [68]. | Struggles with global structure; slow for large n. |
| UMAP [68] | Nonlinear | Balanced local/global | Top-tier in clustering drug responses & MOAs [68]. | Better global structure than t-SNE; faster. |
| PaCMAP [68] | Nonlinear | Balanced local/global | Consistently top-ranked across metrics [68]. | Designed for strong local/global balance. |
| PHATE [68] | Nonlinear | Trajectory/continuity | Strong for dose-dependent, gradual changes [68]. | Excellent for developmental trajectories. |
| Spectral [68] | Nonlinear | Manifold structure | Good for subtle, dose-dependent changes [68]. | Based on graph Laplacian. |
| Autoencoders (AEs) [69] [67] | Nonlinear, Deep Learning | Data-driven features | Balances reconstruction and interpretability [69]. | Flexible; requires more data and tuning. |
A landmark 2025 benchmark of 30 DR methods on drug-induced transcriptomic data (CMap dataset) provided critical insights. The study evaluated methods on their ability to preserve biological similarity under various conditions, such as different cell lines, drugs, and mechanisms of action (MOAs). t-SNE, UMAP, PaCMAP, and TRIMAP consistently ranked in the top five, outperforming standard PCA [68]. This finding is crucial for stem cell research, where distinguishing distinct cell states is paramount.
The benchmark further revealed that most DR methods struggle to capture subtle, dose-dependent transcriptomic changes. In this specific context, Spectral, PHATE, and t-SNE showed stronger performance [68]. This is directly relevant to studying stem cell differentiation, which often involves continuous, gradual transitions rather than discrete jumps. PHATE's design, which models diffusion-based geometry to reflect manifold continuity, makes it particularly well-suited for such biological trajectories [68].
The Critical Role of Hyperparameters and Metrics
A key finding across benchmarks is that default parameters often limit optimal performance. The effectiveness of a DR method is not intrinsic but depends on careful hyperparameter optimization [68]. Furthermore, metric selection is critical for reliable evaluation. Studies use a combination of internal validation metrics (e.g., Silhouette Score, Davies-Bouldin Index), which assess cluster compactness and separation without ground truth, and external validation metrics (e.g., Adjusted Rand Index (ARI), Normalized Mutual Information (NMI)), which compare clustering results to known labels [5] [68]. These metrics often show high concordance, providing confidence in performance rankings [68].
Integrated Clustering Performance
The Full Analytical Pipeline
The ultimate test for FS and DR methods is their performance in the final clustering of cells into biologically meaningful subpopulations. A comprehensive 2025 benchmark of 28 single-cell clustering algorithms on paired transcriptomic and proteomic data provides direct guidance for stem cell researchers [5].
The study evaluated methods based on ARI, NMI, clustering accuracy, purity, peak memory, and running time. The top-performing methods for overall accuracy across both transcriptomic and proteomic data were scAIDE, scDCC, and FlowSOM [5]. FlowSOM was additionally noted for its excellent robustness. The ranking demonstrates that modern deep learning-based methods (scAIDE, scDCC) can achieve high performance, while well-established algorithms like FlowSOM remain highly competitive.
Balancing Accuracy, Efficiency, and Robustness
Different research scenarios prioritize different aspects of performance. The benchmark provides the following actionable recommendations [5]:
- For Top Performance: Choose scAIDE, scDCC, or FlowSOM.
- For Memory Efficiency: Opt for scDCC or scDeepCluster.
- For Time Efficiency: TSCAN, SHARP, and MarkovHC are recommended.
- For a Balanced Approach: Community detection-based methods (e.g., Leiden, Louvain) offer a good compromise.
This benchmarking also revealed that the performance of some methods is modality-specific. For instance, CarDEC and PARC performed well in transcriptomics but their rankings dropped significantly when applied to proteomic data, highlighting the importance of considering data type when selecting an algorithm [5].
Experimental Protocols & Workflows
Standardized Benchmarking Methodology
The insights in this guide are drawn from rigorous, large-scale benchmark studies that follow a standardized methodology to ensure fairness and reproducibility. A typical workflow is as follows [5] [64] [68]:
- Dataset Curation: Multiple public datasets (e.g., from SPDB, CMap, CWRU) with known ground truth labels are selected. These datasets encompass a variety of tissues, cell types, and technical conditions.
- Data Preprocessing: Raw data is uniformly processed, which includes normalization, filtering, and (in most cases) the application of different FS methods to create various input feature sets.
- Method Execution: All competing algorithms are run on the same preprocessed datasets using consistent computational resources. For DR and clustering methods, hyperparameters are often tuned, though the use of defaults is also tested to simulate real-world conditions.
- Performance Quantification: A wide array of metrics is computed. For clustering, ARI and NMI are standard [5]. For DR, internal metrics (Silhouette Score) and external metrics (ARI after clustering) are used [68]. Runtime and peak memory usage are also tracked.
- Result Aggregation and Scaling: Metric scores are often scaled relative to baseline methods (e.g., using all features, random features) to enable cross-dataset and cross-metric comparisons [64].
- Robustness Assessment: Many studies use simulated datasets with controlled noise levels and varying sizes to assess method robustness [5].
Protocol for Stem Cell Subpopulation Identification
Based on the consolidated benchmark findings, the following step-by-step protocol is recommended for researchers identifying stem cell subpopulations from scRNA-seq data:
- Feature Selection: Apply a batch-aware Highly Variable Genes (HVG) selection method. If your data originates from a single batch, standard HVG selection is sufficient. Select between 2,000 and 5,000 features as a starting point [64].
- Dimensionality Reduction: Project the selected features into a lower-dimensional space using UMAP or PaCMAP for clear cluster separation, or PHATE if investigating a continuous differentiation trajectory [68].
- Clustering: Perform clustering on the DR embeddings. For the highest accuracy, use a top-performing method like scDCC or scAIDE. For a fast and robust analysis, FlowSOM or the Leiden algorithm are excellent choices [5].
- Validation and Interpretation: Validate the resulting clusters using ARI/NMI if ground truth is available. Biologically interpret the subpopulations by identifying their marker genes from the selected feature set and contextualizing them within known stem cell biology.
The Scientist's Toolkit
Table 3: Essential Research Reagents & Computational Tools
| Item / Resource | Function / Description | Relevance to Stem Cell Research |
|---|---|---|
| Paired Multi-omics Datasets [5] | Datasets (e.g., CITE-seq) with paired transcriptome and proteome from same cells. | Provides ground truth for benchmarking; enables cross-modal validation of identified subpopulations. |
| SPDB Database [5] | A large single-cell proteomic database. | Source of diverse, up-to-date datasets for analysis and method testing. |
| HVG Selection (scanpy) [64] | Standardized algorithm for selecting highly variable genes. | Foundational preprocessing step to reduce noise and focus on biologically relevant genes. |
| Adjusted Rand Index (ARI) [5] | Metric for comparing clustering results to known labels. | Quantifies how well computational clusters recapitulate known or manually annotated cell types. |
| Normalized Mutual Info (NMI) [5] | Information-theoretic metric for clustering validation. | Another robust metric for assessing cluster quality against a ground truth. |
| Benchmarking Frameworks (e.g., scIB) [64] | Predefined pipelines for fair method comparison. | Allows researchers to evaluate new methods or assess performance on their specific data. |
In stem cell research, the identification of distinct subpopulations is crucial for understanding differentiation pathways, regenerative potential, and disease mechanisms. Single-cell RNA sequencing (scRNA-seq) has become an indispensable tool in this endeavor, with clustering algorithms serving as the computational foundation for discerning cellular heterogeneity. However, these algorithms present researchers with significant trade-offs between clustering accuracy, memory consumption, and runtime efficiency. This guide objectively compares the performance of contemporary clustering algorithms through the lens of recent benchmarking studies, providing stem cell researchers with evidence-based recommendations for selecting methods that best align with their computational constraints and research objectives.
Performance Comparison of Clustering Algorithms
Recent large-scale benchmarking studies have systematically evaluated numerous clustering algorithms across multiple dimensions of performance. The table below summarizes key findings from these evaluations, highlighting the trade-offs between accuracy, memory efficiency, and runtime.
Table 1: Comprehensive Performance Comparison of Single-Cell Clustering Algorithms
| Clustering Method | Type | Transcriptomic ARI (Rank) | Proteomic ARI (Rank) | Memory Efficiency | Time Efficiency | Recommended Use Case |
|---|---|---|---|---|---|---|
| scAIDE | Deep Learning | 2nd | 1st | Medium | Medium | Top overall accuracy across omics |
| scDCC | Deep Learning | 1st | 2nd | High | Medium | Memory-efficient high accuracy |
| FlowSOM | Classical Machine Learning | 3rd | 3rd | Medium | Medium | Robust performance across data types |
| TSCAN | Classical Machine Learning | - | - | Medium | High | Time-critical applications |
| SHARP | Classical Machine Learning | - | - | Medium | High | Large-scale datasets |
| MarkovHC | Classical Machine Learning | - | - | Medium | High | Fast processing needs |
| scDeepCluster | Deep Learning | - | - | High | Medium | Memory-constrained environments |
| PARC | Community Detection | 5th (Transcriptomics) | 18th (Proteomics) | Variable | Variable | Transcriptomic-specific applications |
| CarDEC | Deep Learning | 4th (Transcriptomics) | 16th (Proteomics) | Variable | Variable | Transcriptomic-specific applications |
The benchmarking data reveals that deep learning methods like scAIDE and scDCC generally achieve superior accuracy across both transcriptomic and proteomic data types, making them particularly suitable for stem cell research where precise population identification is critical [5]. However, these methods typically demand greater computational resources. For researchers working under significant time constraints, classical machine learning approaches like TSCAN, SHARP, and MarkovHC offer the fastest processing times while maintaining respectable accuracy [5]. Community detection-based methods provide a balanced compromise between these competing demands.
Experimental Protocols and Methodologies
Benchmarking Framework Design
The performance data presented in this guide derives from rigorously designed benchmarking studies that employed standardized evaluation methodologies. The primary benchmarking framework assessed 28 clustering algorithms across 10 paired transcriptomic and proteomic datasets encompassing over 300,000 cells and 50 cell types [5]. This extensive design ensured robust performance generalizability across diverse biological contexts relevant to stem cell research.
The evaluation protocol incorporated multiple metrics to comprehensively assess algorithm performance:
- Clustering Accuracy: Measured using Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Clustering Accuracy (CA), and Purity metrics [5]
- Computational Efficiency: Evaluated through peak memory consumption and total running time measurements [5]
- Robustness Assessment: Tested using 30 simulated datasets with varying noise levels and dataset sizes [5]
- Biological Validity: Examined by investigating the impact of highly variable genes (HVGs) and cell type granularity on clustering performance [5]
Multi-Omics Integration Protocols
For stem cell studies incorporating both transcriptomic and proteomic data, benchmarking studies employed seven state-of-the-art integration methods (moETM, sciPENN, scMDC, totalVI, JTSNE, JUMAP, and MOFA+) to fuse paired data modalities [5]. The performance of single-omics clustering algorithms was then assessed on these integrated features, providing guidance for complex multi-omics stem cell applications.
Table 2: Key Research Reagents and Computational Tools
| Resource Type | Specific Tool/Dataset | Function in Analysis |
|---|---|---|
| Clustering Algorithms | scDCC, scAIDE, FlowSOM | Identify cell subpopulations from single-cell data |
| Integration Methods | sciPENN, MOFA+, totalVI | Fuse multiple data modalities (e.g., transcriptome + proteome) |
| Evaluation Metrics | Adjusted Rand Index (ARI), Normalized Mutual Information (NMI) | Quantify clustering accuracy against ground truth |
| Benchmark Datasets | SPDB databases, Seurat v3 datasets | Provide standardized testing platforms with ground truth annotations |
| Spatial Transcriptomics Tools | GraphST, SPIRAL, PRECAST | Integrate spatial context with gene expression data |
Visualizing Computational Trade-offs
The relationship between accuracy, memory, and runtime in clustering algorithms represents a complex trade-off space that can be visualized through the following computational workflow:
Computational Trade-offs in Clustering Algorithm Selection
Analysis of Performance Patterns
The "Weakest Link" Phenomenon in Computational Workflows
Recent benchmarking of multi-slice integration methods has revealed a crucial consideration for complex stem cell analysis pipelines: the "weakest link" phenomenon [70]. This principle demonstrates that poor performance in upstream computational steps (such as data integration) can substantially degrade downstream analysis quality (including clustering results), even when using optimal clustering algorithms [70]. This interdependence highlights the importance of considering the entire computational workflow rather than focusing exclusively on individual algorithm selection.
Data Characteristic Considerations
Algorithm performance exhibits significant dependence on dataset-specific characteristics, including technology platform, cell population complexity, and data sparsity [70]. For stem cell research involving rare subpopulations, methods specifically designed to handle imbalanced cell type distributions may be preferable. Furthermore, research indicates that sequence length and identity significantly impact clustering efficiency, with effects on speed and memory consumption that can exceed an order of magnitude [71].
Recommendations for Stem Cell Research Applications
Scenario-Specific Algorithm Selection
Based on the comprehensive benchmarking evidence:
- For maximum clustering accuracy in identifying subtle stem cell subpopulations, select scAIDE or scDCC, which achieved top rankings across both transcriptomic and proteomic data [5].
- For memory-constrained environments (e.g., personal laptops or shared computing resources), implement scDCC or scDeepCluster, which provide high memory efficiency without substantial accuracy compromises [5].
- For time-sensitive analyses or large-scale stem cell atlas projects, employ TSCAN, SHARP, or MarkovHC, which offer the fastest processing times while maintaining reasonable accuracy [5].
- For multi-omics stem cell studies integrating transcriptomic and proteomic data, apply integration methods like sciPENN or totalVI before clustering to leverage complementary information across modalities [5].
Emerging Methods and Future Directions
Novel approaches like K-volume clustering introduce geometrically interpretable criteria that may offer advantages for capturing complex developmental hierarchies in stem cell systems [72]. Additionally, methods specifically addressing over-clustering, such as recall (calibrated clustering with artificial variables), show promise for preventing biologically misleading results in downstream differential expression analysis [73].
As spatial transcriptomics technologies advance, integration methods like GraphST, Banksy, and MENDER are becoming increasingly relevant for stem cell research in tissue contexts, enabling joint analysis of multiple tissue sections while preserving spatial relationships [70]. These approaches will be particularly valuable for investigating stem cell niches and positional effects in developing tissues.
The ongoing development of clustering algorithms continues to refine the balance between computational demands and biological insights. By selecting methods aligned with specific research questions and resource constraints, stem cell researchers can optimize their computational workflows to maximize discovery potential while maintaining practical feasibility.
Clustering serves as an essential tool in biomedical research, frequently deployed to identify patterns and subgroups within complex, high-dimensional datasets such as gene expression profiles, metabolomics data, and for patient stratification [74]. In the specific context of stem cell research, the precise identification of cell subpopulations, including rare cancer stem cells, is critical for understanding cellular heterogeneity, differentiation trajectories, and disease mechanisms [75] [76]. However, this task presents significant challenges due to the inherent noisiness, high dimensionality, and presence of outliers in single-cell data, which can lead to unreliable or biologically uninterpretable clustering results [74].
To address these challenges, advanced clustering methodologies like trimmed clustering and sparse clustering have been developed. Trimmed clustering enhances robustness by systematically excluding outliers, while sparse clustering emphasizes significant features and suppresses noise [74]. The implementation of these methods has been hampered by the difficulty of manually tuning key parameters, such as the trimming proportion and sparsity level. Recent advancements focus on automating these processes, thereby increasing usability and promoting reproducibility in data-driven biomedical discoveries [74]. This guide provides a comparative benchmark of current automated solutions, evaluating their performance for identifying stem cell subpopulations.
Comparative Performance Benchmarking
A comprehensive benchmark analysis published in Genome Biology (2025) evaluated 28 single-cell clustering algorithms across 10 paired transcriptomic and proteomic datasets, providing critical insights into their performance for cell type identification [5]. The study assessed methods based on the Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), computational resource requirements, and robustness.
Table 1: Overall Performance Ranking of Top Clustering Algorithms (Adapted from [5])
| Algorithm | Overall Ranking (Transcriptomics) | Overall Ranking (Proteomics) | Key Methodology | Robustness |
|---|---|---|---|---|
| scAIDE | 2 | 1 | Deep Learning | High |
| scDCC | 1 | 2 | Deep Learning | High |
| FlowSOM | 3 | 3 | Centroid-Based | Excellent |
| PARC | 5 | 18 | Community Detection | Moderate |
| CarDEC | 4 | 16 | Deep Learning | Low |
The benchmarking revealed that scAIDE, scDCC, and FlowSOM consistently achieved top-tier performance across both transcriptomic and proteomic data modalities [5]. FlowSOM was notably highlighted for its excellent robustness. In contrast, some methods like PARC and CarDEC, while performing well in transcriptomics, experienced significant performance drops when applied to proteomic data, indicating a lack of cross-modal generalization [5].
For users with specific resource constraints, the study provided further recommendations: scDCC and scDeepCluster are recommended for memory efficiency, while TSCAN, SHARP, and MarkovHC are optimal for time efficiency. Community detection-based methods generally offer a balanced compromise between performance and resource consumption [5].
Experimental Protocol for Benchmarking
The experimental protocol employed in the benchmark study offers a template for rigorous clustering evaluation [5]:
- Dataset Curation: Ten real datasets from five tissue types were obtained from SPDB (Single-Cell Proteomic Database) and Seurat v3, encompassing over 50 cell types and 300,000 cells. These included paired single-cell mRNA expression and surface protein expression data generated via CITE-seq, ECCITE-seq, and Abseq technologies [5].
- Algorithm Selection: A total of 28 clustering algorithms were selected, representing diverse methodological categories: 15 classical machine learning-based methods, 6 community detection-based methods, and 7 deep learning-based methods.
- Performance Metrics: Clustering results were evaluated against known ground-truth cell type labels using ARI, NMI, Clustering Accuracy (CA), and Purity. Running time and peak memory usage were also recorded.
- Robustness Assessment: The impact of Highly Variable Genes (HVGs) and cell type granularity was investigated. Thirty simulated datasets with varying noise levels and dataset sizes were used to further assess robustness.
- Multi-omics Integration: Seven feature integration methods (e.g., moETM, sciPENN, totalVI) were used to fuse paired transcriptomic and proteomic data, and single-omics clustering algorithms were subsequently applied to the integrated features.
Specialized Clustering Algorithms and Workflows
Beyond the broadly benchmarked methods, specialized algorithms have been developed to address specific analytical challenges, such as determining the optimal number of clusters or detecting hierarchies within cell populations.
Automated Trimmed and Sparse Clustering
A significant innovation is the development of an automated trimmed and sparse clustering method, which simultaneously determines the optimal number of clusters, the trimming proportion, and the sparsity level [74]. This automation is a major advantage over traditional approaches that require manual, trial-and-error-based tuning of these parameters. This method has been implemented in the evaluomeR package, making it accessible to biomedical researchers without extensive computational backgrounds [74].
Diagram 1: Automated Trimmed and Sparse Clustering Workflow
Multiscale Clustering for Hierarchical Cell Structures
For dissecting complex cellular hierarchies, Multiscale Clustering (MSC) provides a powerful alternative [75]. MSC employs a top-down clustering approach to iteratively split a parent cell network into more coherent and compact subnetworks, ultimately constructing a hierarchical model of cell types and subtypes.
Table 2: Key Research Reagent Solutions for Computational Analysis
| Research Reagent / Software | Type | Primary Function in Analysis |
|---|---|---|
| evaluomeR R Package | Software | Implements automated trimmed and sparse clustering. |
| Multiscale Clustering (MSC) | Algorithm | Unsupervised identification of cell types/subtypes across multiple resolutions. |
| Locally Embedded Network (LEN) | Method | Constructs sparse cell-cell correlation networks to improve resolution limits. |
| AdaptSplit | Algorithm | An adaptive top-down method that searches for the most granular clustering solution at each split. |
| Seurat | Software Toolkit | A comprehensive R package for single-cell genomics, often used as a benchmark and integration tool. |
A critical component of the MSC framework is its novel Locally Embedded Network (LEN) for constructing the cell similarity network. Unlike traditional k-nearest neighbor (kNN) networks, LEN deterministically identifies nearest neighbors using a graph embedding technique on a topological sphere, which results in a sparser and more accurate network [75]. Systematic evaluation on simulated scRNA-seq data demonstrated that LEN consistently produced the sparsest networks while effectively capturing true clustering structures across a broad spectrum of data noise, including varying dropout rates and library sizes [75].
Diagram 2: Multiscale Clustering (MSC) Top-Down Workflow
The iterative splitting process is governed by AdaptSplit, which assesses child clusters against their parent based on improvements in compactness and intra-cluster connectivity. The process continues until no child cluster shows improved quality, finalizing the cell hierarchy [75]. This approach is particularly valuable for identifying novel disease-associated cell subtypes and mechanisms without prior supervision.
The comprehensive benchmarking of clustering algorithms reveals that no single method is universally superior. The choice of an optimal algorithm depends on the specific data modality, the biological question, and computational constraints. For top performance in identifying stem cell subpopulations, scAIDE, scDCC, and FlowSOM are highly recommended based on their robust performance across multiple metrics and data types [5].
The emergence of automated trimmed and sparse clustering solves a critical usability problem by eliminating the need for manual parameter tuning, thus enhancing reproducibility [74]. Furthermore, specialized workflows like Multiscale Clustering (MSC) offer a powerful, data-driven strategy for unraveling complex cellular hierarchies, which is fundamental for discovering novel stem cell subpopulations [75]. As single-cell technologies continue to evolve, integrating these advanced clustering methods into standardized analytical pipelines will be crucial for driving discoveries in stem cell biology and therapeutic development.
Validation Strategies and Performance Metrics: Ensuring Biologically Meaningful Results
In single-cell RNA sequencing (scRNA-seq) analysis, clustering serves as a fundamental step for identifying distinct cell populations, a critical process in stem cell research for understanding cellular heterogeneity, developmental pathways, and differentiation states. The performance of clustering algorithms directly impacts the reliability of downstream biological interpretations, making rigorous evaluation essential. Benchmarking studies systematically assess algorithm performance using standardized metrics and datasets, providing researchers with evidence-based guidance for method selection. Within the specific context of stem cell subpopulation identification, accurate clustering can reveal rare progenitor cells, delineate differentiation trajectories, and identify novel cellular states, thereby accelerating discovery in regenerative medicine and drug development.
This guide focuses on four core metrics—Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Purity, and Cluster Accuracy (CA)—that are widely used for quantifying clustering performance against known reference annotations. The objective evaluation of these metrics allows researchers to select the most appropriate clustering tools for their specific experimental needs, balancing accuracy, computational efficiency, and robustness.
Defining the Key Clustering Metrics
Metric Definitions and Calculations
Clustering evaluation metrics quantify the agreement between a computational clustering result and a ground truth partition of the data, such as manually annotated cell types or known sample origins.
- Adjusted Rand Index (ARI): The ARI quantifies the similarity between two data clusterings by considering all pairs of samples and counting the pairs that are assigned to the same or different clusters in the predicted and true clusterings. It is adjusted for chance, meaning that the expected value of the ARI is 0.0 for random labeling, and 1.0 signifies perfect agreement. This adjustment makes it a robust measure for comparing clusterings across different datasets and algorithms [5].
- Normalized Mutual Information (NMI): NMI is an information-theoretic measure that assesses the mutual dependence between the two clusterings. It is based on the concept of entropy, measuring how much knowledge about the ground truth clustering is revealed by the computational clustering result. The value is normalized to a range of [0, 1], where 0 indicates no mutual information and 1 indicates perfect correlation [5].
- Purity: Purity is a simple and intuitive metric. It is calculated by assigning each cluster to the class which is most frequent in that cluster, and then counting the number of correctly assigned cells and dividing by the total number of cells. While easy to interpret, a potential weakness is that it does not penalize over-clustering (i.e., splitting a true class into multiple small clusters) [5].
- Cluster Accuracy (CA): Cluster Accuracy, also referred to as clustering accuracy, is another widely used metric that finds a one-to-one mapping between computational clusters and true classes to maximize the number of correctly assigned cells. It is similar in spirit to Purity but involves a more formal matching process, often using the Hungarian algorithm to find this optimal matching [5].
Metric Strengths, Weaknesses, and Biological Interpretation
Table 1: Characteristics and Interpretation of Primary Clustering Metrics
| Metric | Range of Values | Key Strength | Key Weakness / Consideration | Biological Interpretation in Stem Cell Research |
|---|---|---|---|---|
| Adjusted Rand Index (ARI) | -1 to 1 | Corrected for chance, making comparisons fair. | Can be sensitive to the number of clusters and cluster sizes. | High ARI suggests the algorithm correctly groups cells with shared transcriptional programs (e.g., pluripotent vs. differentiated states). |
| Normalized Mutual Information (NMI) | 0 to 1 | Information-theoretic; robust to different numbers of clusters. | Can be overly optimistic when the number of clusters is large. | High NMI indicates the clustering result captures most of the "information" about the known cell type identities. |
| Purity | 0 to 1 | Simple and highly intuitive to understand. | Does not penalize for splitting a true cell type into many small clusters. | Reflects the homogeneity of the identified clusters. High purity means most clusters are dominated by a single, true cell type. |
| Cluster Accuracy (CA) | 0 to 1 | Uses optimal matching, providing a direct accuracy measure. | The matching process can be computationally intensive for a very large number of clusters. | Similar to purity, a high CA score indicates successful one-to-one matching of computational clusters to biological cell types. |
Benchmarking Clustering Algorithms for Single-Cell Data
Experimental Protocols from a Comprehensive Benchmark
A recent large-scale benchmarking study provides a robust experimental framework for evaluating clustering algorithms, which is directly applicable to stem cell research [5]. The methodology can be summarized as follows:
- Algorithm Selection and Datasets: The study benchmarked 28 computational algorithms, categorized into classical machine learning-based methods (e.g., SC3, TSCAN), community detection-based methods (e.g., Leiden, Louvain), and deep learning-based methods (e.g., scDCC, scAIDE). The evaluation was conducted on 10 paired single-cell transcriptomic and proteomic datasets, encompassing over 50 cell types and more than 300,000 cells. These datasets were obtained using multi-omics technologies like CITE-seq, ensuring that the mRNA and protein expression data were measured from the same set of cells, which provides a consistent biological ground for cross-modal analysis [5].
- Evaluation Workflow and Robustness Testing: The standard workflow involved applying each clustering algorithm to the datasets and comparing the output labels to the known ground truth cell type labels using ARI, NMI, CA, and Purity. To ensure robust conclusions, the study also investigated the impact of key analytical steps, such as the selection of Highly Variable Genes (HVGs), and assessed performance across cell types of varying granularity. Furthermore, the robustness of these methods was rigorously evaluated using 30 simulated datasets with varying noise levels and dataset sizes [5].
- Performance Ranking Strategy: Algorithms were ranked based on an overall strategy that aggregated their performance across the primary metrics (ARI and NMI) and multiple datasets. This approach provides a consolidated view of an algorithm's general performance [5].
The following workflow diagram illustrates the key stages of this large-scale benchmarking process:
Diagram Title: Benchmarking Workflow
Comparative Performance of Top-Tier Algorithms
The benchmarking study revealed that a subset of algorithms consistently achieved top performance across both transcriptomic and proteomic data modalities [5].
Table 2: Top-Performing Clustering Algorithms from Benchmarking
| Algorithm | Overall Ranking (Transcriptomics) | Overall Ranking (Proteomics) | Key Characteristic | Notable Strength |
|---|---|---|---|---|
| scAIDE | 2 | 1 | Deep learning-based | Top performance on proteomic data; uses autoencoder and hashing [5] [39]. |
| scDCC | 1 | 2 | Deep learning-based | Best performance on transcriptomic data; also memory-efficient [5]. |
| FlowSOM | 3 | 3 | Classical machine learning | Excellent robustness and consistently high performance across omics types [5]. |
Key Findings and Cross-Modal Insights:
- The top three methods—scDCC, scAIDE, and FlowSOM—demonstrated strong generalization capability by performing well on both transcriptomic and proteomic data, despite the differing data distributions and feature dimensionalities between these modalities [5].
- Performance was not always transferable. For example, CarDEC and PARC ranked 4th and 5th, respectively, in transcriptomics, but their rankings dropped significantly to 16th and 18th in proteomics. This highlights the importance of selecting algorithms validated for the specific data modality in use [5].
- Beyond the top performers, scDeepCluster and TSCAN, SHARP, and MarkovHC were highlighted for their strengths in memory efficiency and time efficiency, respectively, offering valuable alternatives for researchers with specific computational constraints [5].
Advanced Considerations for Reliable Clustering
The Critical Issue of Clustering Consistency
A significant challenge in scRNA-seq clustering is consistency. Many popular graph-based clustering algorithms (e.g., Leiden, Louvain) rely on stochastic processes, meaning their results can vary from run to run depending on the random seed. This inconsistency can undermine the reliability of biological conclusions, as a cluster of interest (e.g., a putative rare stem cell subpopulation) might disappear in a subsequent analysis run [26].
To address this, methods like the single-cell Inconsistency Clustering Estimator (scICE) have been developed. scICE efficiently evaluates clustering consistency by running the Leiden algorithm multiple times with different random seeds and calculating an Inconsistency Coefficient (IC). An IC close to 1 indicates highly consistent and reliable results, while a higher IC signals instability. This tool can identify unreliable clustering outcomes and help researchers focus on stable, reproducible cell populations, which is crucial for robust stem cell subpopulation identification [26].
Identifying Rare Cell Populations
A specific and biologically important task in stem cell research is the identification of rare cell populations, such as transient progenitors or tissue-specific stem cells. Standard clustering algorithms like SC3, while robust for identifying abundant cell types, often fail to detect these rare populations [39]. Specialized methods have been developed to address this challenge:
- ProgClust: A progressive clustering method that grows clustering trees. It uses Fano factor-based clustering to identify abundant cell types and then employs Gini index-based detection locally to find rare cells mixed within the abundant populations. This approach is designed to automatically determine the number of clusters and reveal the structure of both abundant and rare cell populations [39].
- scSID: A lightweight algorithm that identifies rare cell types by performing a deep analysis of both inter-cluster and intra-cluster similarities, discovering rare cells based on similarity differences [63].
The integration of these specialized tools into the analytical pipeline can significantly enhance the discovery power for rare stem cell subtypes.
Essential Research Reagent Solutions
The following table details key reagents, tools, and software essential for conducting clustering benchmarking experiments or performing single-cell data analysis in a stem cell research context.
Table 3: Key Reagent Solutions for Single-Cell Clustering Research
| Item Name | Type (Software/Data/Reagent) | Primary Function in Research | Example/Note |
|---|---|---|---|
| CITE-seq | Technology & Reagent | Simultaneously measures mRNA and surface protein expression in single cells, generating paired multi-omics data for benchmarking [5]. | A cornerstone technology for creating datasets with robust ground truth. |
| SPDB | Data Resource | A large single-cell proteomic database providing access to extensive and up-to-date datasets for testing clustering algorithms [5]. | Served as a source for 9 of the 10 datasets in the benchmark study [5]. |
| Leiden Algorithm | Software Algorithm | A fast and widely used graph-based clustering algorithm that is common in scRNA-seq analysis but exhibits stochasticity [26]. | Often the default in popular toolkits; its consistency can be evaluated with scICE [26]. |
| scICE Tool | Software Tool | Evaluates clustering consistency by calculating an Inconsistency Coefficient (IC), ensuring results are reliable across multiple runs [26]. | Critical for verifying that identified stem cell subpopulations are reproducible. |
| Induced Pluripotent Stem Cells (iPSCs) | Biological Reagent | Patient-specific stem cells used in therapy development; their analysis requires precise clustering to ensure quality and differentiation status [77] [78]. | A key application area for clustering in regenerative medicine. |
Based on the comprehensive benchmarking data, researchers in stem cell biology should consider the following evidence-based recommendations when selecting clustering algorithms for subpopulation identification:
- For top overall performance on single-cell data, particularly when analyzing both transcriptomic and proteomic data, the deep learning methods scAIDE and scDCC, as well as FlowSOM, are highly recommended [5].
- If computational efficiency is a primary concern, scDCC and scDeepCluster are recommended for memory efficiency, while TSCAN, SHARP, and MarkovHC are excellent choices for time efficiency [5].
- To ensure the reliability and reproducibility of your clustering results, especially when publishing findings on novel stem cell populations, it is critical to assess clustering consistency using tools like scICE [26].
- For the specific task of identifying rare stem cell populations (e.g., progenitors), general-purpose top performers may not be sufficient. Incorporating specialized tools like ProgClust or scSID into the analysis pipeline is strongly advised [39] [63].
By leveraging these metrics, benchmarks, and specialized tools, researchers can make informed, data-driven decisions in their computational workflows, leading to more robust, reliable, and biologically insightful identification of stem cell subpopulations.
Benchmarking on Real and Simulated Stem Cell Datasets
Single-cell RNA sequencing (scRNA-seq) has revolutionized stem cell research by enabling the precise characterization of cellular heterogeneity and the identification of previously unrecognized subpopulations. Clustering analysis serves as a fundamental step in this process, allowing researchers to group cells with similar transcriptomic profiles into distinct populations that may represent different stem cell states, lineages, or transitional phases. However, the selection of an appropriate clustering algorithm is complicated by the proliferation of available methods, each with distinct strengths, weaknesses, and underlying computational approaches. This benchmarking study provides a systematic evaluation of single-cell clustering algorithms specifically within the context of stem cell research, offering evidence-based guidance for researchers investigating stem cell biology, developmental processes, and regenerative medicine applications. By assessing algorithm performance on both real and simulated stem cell datasets, we aim to identify methods that most accurately recover known biological truths while remaining computationally efficient and robust to dataset-specific characteristics common in stem cell studies.
Performance Comparison of Clustering Algorithms
We evaluated 28 clustering algorithms on 10 paired transcriptomic and proteomic datasets, assessing their performance using multiple metrics including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), clustering accuracy, purity, peak memory usage, and running time [5]. The algorithms were categorized into three methodological groups: classical machine learning-based methods, community detection-based approaches, and deep learning-based techniques. This comprehensive evaluation revealed substantial differences in performance across methods, with the top performers consistently outperforming others across both transcriptomic and proteomic data modalities.
Table 1: Top-Performing Clustering Algorithms for Stem Cell Data Analysis
| Algorithm | Overall Ranking | Transcriptomics Performance | Proteomics Performance | Computational Efficiency | Robustness |
|---|---|---|---|---|---|
| scAIDE | 1 | Excellent | Excellent | Moderate | High |
| scDCC | 2 | Excellent | Excellent | Memory-efficient | High |
| FlowSOM | 3 | Excellent | Excellent | Fast | Excellent |
| CarDEC | 4 (transcriptomics) | Excellent | Moderate | Moderate | Moderate |
| PARC | 5 (transcriptomics) | Excellent | Moderate | Fast | Moderate |
| TSCAN | 6 | Good | Good | Time-efficient | Moderate |
| SHARP | 7 | Good | Good | Time-efficient | Moderate |
| MarkovHC | 8 | Good | Good | Time-efficient | Moderate |
Modality-Specific Performance Considerations
Our analysis revealed that while several top-performing algorithms demonstrated consistent performance across both transcriptomic and proteomic data, some methods exhibited significant modality-specific performance variations [5]. For instance, CarDEC and PARC ranked 4th and 5th respectively for transcriptomic data, but their rankings dropped significantly to 16th and 18th for proteomic data. This highlights the importance of selecting algorithms that are appropriate for the specific data modality being analyzed. For researchers working specifically with single-cell proteomic data, which often exhibits different data distributions and feature dimensionalities compared to transcriptomic data, scAIDE, scDCC, and FlowSOM are particularly recommended based on their robust cross-modal performance [5].
Computational Efficiency Trade-offs
Different clustering algorithms exhibited substantial variations in their computational demands, enabling researchers to select methods based on their specific resource constraints and analytical priorities [5]. For users prioritizing memory efficiency, scDCC and scDeepCluster are recommended, while TSCAN, SHARP, and MarkovHC are optimal for those requiring time efficiency [5]. Community detection-based methods generally offered a balanced approach between computational demands and clustering performance. These efficiency considerations are particularly relevant for stem cell researchers working with large-scale datasets, such as those profiling entire differentiation trajectories or multiple experimental conditions.
Experimental Design and Methodologies
Dataset Selection and Preprocessing
Our benchmarking study utilized 10 real datasets across 5 tissue types, encompassing over 50 cell types and more than 300,000 cells, each containing paired single-cell mRNA expression and surface protein expression data [5]. These datasets were obtained from public repositories including SPDB (the largest single-cell proteomic database) and Seurat v3, with the latter providing cell type labels at different levels of granularity particularly valuable for assessing resolution capabilities in stem cell hierarchies [5]. All datasets were generated using multi-omics technologies such as CITE-seq, ECCITE-seq, and Abseq, ensuring consistent biological conditions across modalities.
To evaluate robustness under controlled conditions, we extended our analysis to 30 simulated datasets with varying noise levels and dataset sizes [5]. This approach allowed systematic assessment of how clustering performance degrades with increasing technical variability—a critical consideration for stem cell researchers working with datasets exhibiting different quality parameters or generated across multiple batches.
Evaluation Metrics and Validation Framework
We employed multiple complementary metrics to comprehensively evaluate clustering performance [5]. The Adjusted Rand Index (ARI) quantified clustering quality by comparing predicted and ground truth labels, with values ranging from -1 to 1. Normalized Mutual Information (NMI) measured the mutual information between clustering assignments and ground truth, normalized to [0, 1]. For both metrics, values closer to 1 indicate better clustering performance. Additionally, we assessed clustering accuracy, purity, peak memory usage, and running time to provide a holistic assessment of each algorithm's practical utility.
To address the critical challenge of clustering consistency in scRNA-seq analysis, we incorporated the single-cell Inconsistency Clustering Estimator (scICE) framework, which evaluates clustering consistency across multiple runs with different random seeds [26]. This approach employs the inconsistency coefficient (IC) metric, which quantifies label stability without requiring computationally expensive consensus matrices, achieving up to 30-fold speed improvement compared to conventional consensus clustering-based methods [26].
Figure 1: Comprehensive workflow for benchmarking clustering algorithms on stem cell datasets, encompassing data collection, algorithm categorization, multi-faceted evaluation, and final recommendations.
Advanced Considerations for Stem Cell Research
Addressing Rare Cell Population Identification
Stem cell differentiation often involves rare transitional states that are critical for understanding lineage commitment decisions. To address this challenge, we evaluated specialized methods for rare cell identification, including scCAD (Cluster decomposition-based Anomaly Detection), which employs an iterative clustering approach based on the most differential signals within each cluster to effectively separate rare cell types [44]. In benchmarking across 25 real scRNA-seq datasets, scCAD achieved superior performance (F1 score = 0.4172) with improvements of 24% and 48% compared to the second and third-ranked methods, respectively [44]. This capability is particularly valuable for stem cell researchers investigating rare progenitor populations or transitional states during cellular differentiation.
Ensemble Methods for Enhanced Robustness
Given the methodological bias inherent in individual clustering algorithms, we assessed ensemble approaches that integrate multiple clustering methods to generate more robust and reliable results. scEVE (single-cell RNA-seq ensemble clustering) addresses two grand challenges in single-cell data science: the need to study cells at multiple resolutions and the need to quantify the uncertainty of results [56]. Unlike conventional ensemble algorithms that minimize differences between input clustering results, scEVE describes and leverages these differences to identify clusters robust to methodological variations while preventing over-clustering [56]. This approach is particularly advantageous for stem cell datasets where the "true" number of distinct subpopulations may be ambiguous due to continuous differentiation trajectories.
Impact of Technical Factors on Clustering Performance
Our evaluation investigated several technical factors that significantly impact clustering performance in stem cell data analysis:
- Highly Variable Genes (HVGs): The selection of HVGs substantially influenced clustering outcomes, with optimal feature selection strategies varying depending on data modality and biological context [5].
- Cell Type Granularity: Algorithms demonstrated variable performance at different resolution levels, with some methods excelling at identifying broad cell classes while others were more effective at distinguishing closely related subpopulations [5].
- Data Integration: When integrating paired transcriptomic and proteomic data using 7 state-of-the-art integration methods (including moETM, sciPENN, and totalVI), clustering performance on integrated features was generally enhanced compared to single-modality analysis [5].
Figure 2: Advanced analytical challenges in stem cell clustering and corresponding computational solutions, highlighting the relationship between specific problems and specialized methodologies.
Table 2: Key Research Reagent Solutions for Single-Cell Stem Cell Studies
| Resource Category | Specific Tools | Primary Function | Application Context |
|---|---|---|---|
| Clustering Algorithms | scAIDE, scDCC, FlowSOM | Cell subpopulation identification | General stem cell clustering |
| Rare Cell Detection | scCAD, FiRE, CellSIUS | Identification of low-frequency populations | Stem cell transitional states |
| Ensemble Methods | scEVE, SC3, Seurat | Robust consensus clustering | Methodologically validated results |
| Multi-omics Integration | moETM, sciPENN, totalVI | Integrating transcriptomic & proteomic data | Comprehensive cellular characterization |
| Consistency Evaluation | scICE, multiK, chooseR | Assessing clustering stability | Reliable result verification |
| Benchmarking Platforms | DuoClustering2018, SPDB | Method performance comparison | Algorithm selection guidance |
Based on our comprehensive benchmarking analysis, we provide the following recommendations for researchers performing clustering analysis on stem cell datasets:
- For maximum accuracy across both transcriptomic and proteomic data: Prioritize scAIDE, scDCC, and FlowSOM, as these methods demonstrated top-tier performance in both modalities [5].
- For large-scale studies with computational constraints: Select algorithms based on specific resource limitations—scDCC and scDeepCluster for memory-efficient analysis, or TSCAN, SHARP, and MarkovHC for time-efficient processing [5].
- For identifying rare subpopulations in stem cell hierarchies: Implement scCAD, which demonstrated superior performance in rare cell identification compared to 10 state-of-the-art methods [44].
- For methodologically robust and validated results: Incorporate ensemble approaches like scEVE and consistency evaluation tools like scICE to ensure clustering reliability across multiple runs and methodological approaches [26] [56].
This benchmarking study provides a comprehensive foundation for selecting appropriate clustering algorithms in stem cell research, enabling more accurate and reliable identification of stem cell subpopulations across diverse experimental conditions and data modalities. As single-cell technologies continue to evolve, regular re-assessment of computational methods will be essential for maintaining analytical rigor in stem cell biology.
In the field of stem cell research, single-cell RNA sequencing (scRNA-seq) has become an indispensable tool for unraveling cellular heterogeneity and identifying novel stem cell subpopulations. Clustering analysis serves as the foundational step in this process, enabling researchers to group cells with similar expression profiles and infer potential cellular identities and states. The performance of clustering algorithms, however, is not determined solely by their mathematical formulations but is profoundly influenced by critical experimental factors, primarily cell type granularity and data quality. These factors introduce significant variability in clustering outcomes, affecting the reliability and biological relevance of the identified stem cell subpopulations.
This guide objectively compares the performance of various clustering algorithms under different experimental conditions, providing stem cell researchers with evidence-based recommendations for selecting appropriate methods based on their specific research goals regarding resolution and data characteristics. By synthesizing findings from recent large-scale benchmarking studies, we aim to enhance the rigor and reproducibility of stem cell subpopulation identification in research and drug development contexts.
Impact of Cell Type Granularity
Cell type granularity refers to the level of resolution at which cell types or states are defined, ranging from broad classifications (e.g., "stem cells" versus "differentiated cells") to highly refined subpopulations (e.g., distinct stem cell subtypes or transitional states). The choice of granularity directly impacts the suitability and performance of clustering algorithms.
Algorithm Performance Across Granularity Levels
Recent benchmarking efforts reveal that clustering algorithms exhibit distinct performance characteristics across different levels of cell type granularity. A comprehensive assessment of 28 clustering algorithms on paired transcriptomic and proteomic data demonstrated that methods such as scAIDE, scDCC, and FlowSOM consistently achieved top rankings across both omics modalities, suggesting robust performance regardless of the biological context [5]. However, their relative effectiveness varies when identifying fine-grained subpopulations.
Algorithms optimized for high-resolution clustering, such as DESC, have demonstrated promising capability for stem cell subtype identification and capturing subtle cellular heterogeneity [34]. These methods typically employ sophisticated deep learning architectures or graph-based approaches that can detect nuanced expression patterns characterizing rare stem cell states.
In contrast, some methods exhibit significant performance degradation when transitioning from broad to fine-grained clustering tasks. For instance, CarDEC and PARC maintained strong performance in transcriptomics (ranking 4th and 5th, respectively) but dropped significantly in proteomics (to 16th and 18th) when applied to more refined cell type classifications [5]. This highlights the modality-specific considerations researchers must account for when designing stem cell experiments.
Experimental Protocols for Granularity Assessment
To systematically evaluate algorithm performance across granularity levels, benchmarking studies typically employ the following methodological framework:
Dataset Selection with Multi-level Annotations: Curate datasets with well-established hierarchical annotations (e.g., from coarse to fine: Immune cells → T cells → Naive T cells → Stem cell memory T cells) [79] [80].
Algorithm Application Across Hierarchy Levels: Apply clustering algorithms to the same dataset while varying resolution parameters to generate cluster assignments at different levels of granularity.
Multi-metric Performance Evaluation: Compare cluster assignments to ground truth annotations using multiple complementary metrics:
Consistency Evaluation: Employ tools like popV for consensus prediction [80] or scICE for clustering reliability assessment [26] to quantify stability across granularity levels.
Table 1: Algorithm Performance Across Cell Type Granularity Levels
| Algorithm | Broad Cell Types (e.g., Major Lineages) | Intermediate Subpopulations | Fine-grained Subtypes (e.g., Rare Stem Cells) | Notable Strengths |
|---|---|---|---|---|
| scAIDE [5] | Excellent | Excellent | Excellent | Top performance across omics |
| scDCC [5] | Excellent | Excellent | Excellent | Memory efficient |
| FlowSOM [5] | Excellent | Excellent | Excellent | Robustness |
| DESC [34] | Good | Excellent | Excellent | Captures cellular heterogeneity |
| Seurat [34] | Excellent | Good | Good | Well-established, balanced performance |
| SC3 [34] | Excellent | Good | Fair | Consistently good but computationally slow |
| CosTaL [34] | Excellent | Excellent | Good | Superior for specific cell types |
| scVI [34] | Variable | Variable | Variable | Performance depends on dataset characteristics |
Figure 1: Experimental workflow for evaluating clustering performance across cell type granularity levels, measuring algorithm capability from broad classifications to fine-grained subtype identification.
Impact of Data Quality
Data quality encompasses multiple technical aspects of scRNA-seq data that significantly influence clustering outcomes, including sequencing depth, sparsity (dropout rate), batch effects, and noise levels. Understanding how these factors impact algorithm performance is crucial for selecting robust methods, particularly when working with stem cell data that may exhibit inherent technical challenges.
Technical Factors Affecting Clustering Performance
Data sparsity, characterized by a high proportion of zero counts (dropouts), presents a particular challenge for clustering stem cell populations where critical marker genes may be expressed at low levels or in a burst-like manner. Benchmarking studies have demonstrated that deep learning-based approaches like scDCC and scDeepCluster generally show better robustness to high sparsity levels compared to traditional methods, as their architectures can learn latent representations that are less sensitive to missing values [5].
Batch effects introduced through different experimental preparations, sequencing runs, or even temporal variations can severely confound clustering results. A critical assessment revealed that DESC explicitly addresses this challenge by effectively integrating data while removing batch effects, making it particularly suitable for multi-sample stem cell studies [34]. Similarly, Seurat's graph-based clustering with WNN (Weighted Nearest Neighbors) has demonstrated competence in handling batch effects while preserving biological heterogeneity [34].
Noise levels in scRNA-seq data, arising from both biological and technical sources, disproportionately affect different clustering approaches. Simulation-based evaluations using 30 synthetic datasets with controlled noise parameters have shown that FlowSOM exhibits excellent robustness to varying noise conditions, while community detection-based methods generally offer a balanced trade-off between noise resistance and computational efficiency [5].
Quantitative Impact on Performance Metrics
The consequences of data quality issues are quantifiable through standardized clustering metrics. Studies have reported ARI reductions of 15-40% when applying the same algorithm to datasets with high technical noise compared to clean data from the same biological source [5] [34]. Similarly, NMI scores typically decrease by 10-30% in the presence of strong batch effects when using methods not specifically designed for data integration [34].
Table 2: Algorithm Robustness to Data Quality Challenges
| Algorithm | Robustness to High Sparsity | Batch Effect Correction | Noise Tolerance | Computational Efficiency |
|---|---|---|---|---|
| scDCC [5] | Excellent | Good | Good | High (Memory efficient) |
| FlowSOM [5] | Good | Fair | Excellent | High |
| DESC [34] | Good | Excellent | Good | Medium |
| Seurat [34] | Good | Good | Good | Medium |
| scVI [34] | Variable | Excellent | Variable | Medium |
| SC3 [34] | Fair | Fair | Fair | Low (Slow for large datasets) |
| CosTaL [34] | Good | Good | Good | Medium |
| scDeepCluster [5] | Excellent | Good | Good | High (Memory efficient) |
Experimental Protocols for Data Quality Assessment
Systematic evaluation of algorithm robustness to data quality issues involves carefully controlled experimental designs:
Simulated Data Generation: Create synthetic scRNA-seq datasets with precisely controlled noise levels, dropout rates, and batch effects using tools like Splatter or symmetric datasets with known ground truth [5].
Progressive Degradation Experiments: Take high-quality datasets and systematically introduce technical artifacts (e.g., random dropout, added noise, simulated batch effects) while measuring clustering performance degradation [34].
Stability Assessment: Implement consistency evaluation frameworks like scICE, which quantifies clustering reliability through the Inconsistency Coefficient (IC) by repeatedly applying algorithms with different random seeds [26].
Multi-dataset Validation: Test algorithms across diverse real-world datasets with varying quality characteristics to assess generalizability beyond idealized conditions [34].
Figure 2: Experimental workflow for assessing algorithm robustness to data quality challenges, measuring performance degradation under controlled technical artifacts.
The Scientist's Toolkit
Selecting appropriate computational tools and reagents is essential for successful stem cell subpopulation identification. The following table summarizes key resources mentioned in benchmarking studies and their specific applications in stem cell research.
Table 3: Essential Research Reagent Solutions for Stem Cell Clustering Analysis
| Resource Name | Type | Primary Function | Application Context in Stem Cell Research |
|---|---|---|---|
| scDCC [5] | Clustering Algorithm | Deep learning-based clustering | Identifying subtle stem cell subtypes; memory-efficient processing |
| DESC [34] | Clustering Algorithm | Deep embedding with batch correction | Integrating multiple stem cell datasets; resolving fine-grained heterogeneity |
| FlowSOM [5] | Clustering Algorithm | Self-organizing maps | Rapid analysis of large stem cell datasets; robust performance |
| popV [80] | Annotation Tool | Ensemble cell type prediction | Transferring labels from reference atlases to stem cell data with uncertainty scores |
| scICE [26] | Validation Tool | Clustering consistency evaluation | Assessing reliability of identified stem cell clusters across multiple runs |
| Seurat [34] | Analysis Toolkit | Comprehensive scRNA-seq analysis | Standard workflow for initial stem cell clustering and visualization |
| Cell Ontology [80] | Reference Resource | Standardized cell type hierarchy | Consistent annotation of stem cell populations across studies |
| Side Scatter (SSC) [79] | Physical Property | Cell granularity measurement | Label-free enrichment of favorable T cells for immunotherapy applications |
The selection of clustering algorithms for stem cell subpopulation identification requires careful consideration of both cell type granularity requirements and data quality characteristics. Evidence from comprehensive benchmarking studies indicates that while no single algorithm universally outperforms all others across every scenario, method selection can be optimized based on specific research needs.
For studies aiming to identify rare stem cell subtypes or characterize subtle transitional states, deep learning-based approaches such as scDCC and DESC generally provide superior performance due to their ability to capture complex patterns in high-dimensional data while mitigating technical noise [5] [34]. When working with large-scale datasets or requiring computational efficiency, FlowSOM and community detection-based methods offer an excellent balance of performance and speed [5]. For integrative analyses combining multiple datasets or technologies, DESC and Seurat demonstrate robust batch effect correction capabilities [34].
Regardless of the chosen method, implementing rigorous validation procedures using tools like scICE for consistency assessment [26] and popV for automated annotation with proper uncertainty estimation [80] significantly enhances the reliability of research findings. By aligning algorithmic selection with experimental factors and employing appropriate validation frameworks, stem cell researchers can advance our understanding of cellular heterogeneity with greater confidence and reproducibility.
In stem cell research, accurately identifying distinct subpopulations is fundamental to understanding differentiation, regeneration, and disease. Single-cell clustering algorithms are indispensable for this task, yet their performance must be rigorously validated through biological methods such as functional assays and lineage tracing. Lineage tracing provides the gold standard for mapping cellular fate and lineage relationships by tracking the descendants of a single progenitor cell, thereby revealing complex lineage hierarchies in both normal development and pathological contexts [81]. Concurrently, functional assays test the differential capabilities—such as proliferative potential or differentiation capacity—of the clusters identified by computational methods. This guide provides a comparative benchmark of single-cell clustering algorithms, evaluating their performance against biological validation data derived from these critical techniques. The integration of computational clustering with experimental validation forms a powerful synergy, ensuring that identified cell clusters reflect genuine biological entities with distinct functional roles.
To objectively compare clustering algorithms, we conducted a benchmark based on a recent large-scale study that evaluated 28 computational methods across 10 paired single-cell transcriptomic and proteomic datasets [5]. Performance was assessed using metrics such as the Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI), which measure the congruence between computational clusters and known biological labels, alongside computational efficiency metrics [5].
The table below summarizes the top-performing algorithms from this benchmark, highlighting their respective strengths.
Table 1: Top-Performing Clustering Algorithms for Single-Cell Data
| Algorithm | Overall Performance (Transcriptomics) | Overall Performance (Proteomics) | Key Strength | Computational Efficiency |
|---|---|---|---|---|
| scAIDE | Top 3 [5] | Ranked 1 [5] | High accuracy, excellent robustness | Not specified |
| scDCC | Ranked 1 [5] | Ranked 2 [5] | Top accuracy, memory-efficient | Memory-efficient [5] |
| FlowSOM | Top 3 [5] | Ranked 3 [5] | Excellent robustness, fast | Fast, memory-efficient [5] |
| TSCAN | Not in top 3 [5] | Not in top 3 [5] | Time-efficient | High time-efficiency [5] |
| SHARP | Not in top 3 [5] | Not in top 3 [5] | Time-efficient | High time-efficiency [5] |
This comparative data allows researchers to select algorithms based on their primary need: scAIDE, scDCC, and FlowSOM for top-tier all-around performance and robustness; scDCC and scDeepCluster for memory-constrained environments; and TSCAN or SHARP for projects where time is a critical factor [5].
Experimental Protocols for Biological Validation
Lineage Tracing Methodologies
Lineage tracing techniques provide the foundational experimental framework for validating the lineage relationships suggested by clustering algorithms. Key methodologies include:
Site-Specific Recombinase Systems (e.g., Cre-loxP): This is a cornerstone technique for lineage tracing. In this system, the Cre recombinase enzyme is expressed under a cell-type-specific promoter. It acts on loxP sites in the DNA to excise a "STOP" cassette, thereby permanently activating a reporter gene (e.g., a fluorescent protein) in the target cell and all its progeny. This allows for the precise marking and tracking of a cell's descendants over time [82]. For inducible control, Cre is fused to a mutant estrogen receptor (CreERT2), enabling temporal activation of lineage tracing upon administration of tamoxifen [82].
Multicolour Labeling Systems (e.g., Brainbow/Confetti): These systems leverage the Cre-loxP principle but use complex arrays of multiple fluorescent protein genes and loxP sites. Stochastic Cre recombination creates a unique combination of fluorescent proteins in individual cells, generating a distinct "colour" barcode. This allows researchers to simultaneously track multiple lineages within a single tissue and visualize complex clonal dynamics and cellular interactions [82] [81]. While powerful, achieving single-cell resolution can be challenging due to difficulties in controlling the timing and dosage of Cre induction [81].
DNA Barcode-Based Lineage Tracing: This approach uses introduced or engineered DNA sequences as heritable, traceable markers.
- Integration Barcodes: A library of random DNA barcode sequences is delivered into a population of cells (e.g., hematopoietic stem cells) via retroviral vectors. Each integrating virus marks a progenitor cell with a unique barcode, which is passed to all its clonal descendants. High-throughput sequencing is later used to reconstruct clonal outputs by quantifying barcode abundances in different cell populations [81].
- CRISPR Barcodes: This method uses the CRISPR/Cas9 system to induce accumulating mutations (InDels) in a synthetic, heritable DNA sequence within the genome. The pattern of mutations serves as a record of cell divisions, enabling the reconstruction of high-resolution lineage trees from the sampled cells [81].
Functional Assays for Stem Cell Characterization
Functional assays are critical for testing the biological properties of computationally derived clusters.
Clonal Differentiation Assays: Cells from a purified cluster are isolated and cultured in vitro under conditions that promote multi-lineage differentiation (e.g., into adipogenic, osteogenic, and chondrogenic lineages). The resulting colonies are then stained for lineage-specific markers. This assay confirms whether a cluster contains true multipotent stem or progenitor cells [83].
Transplantation and Regeneration Assays: This is a gold-standard in vivo functional test. Candidate stem cells from a specific cluster are transplanted into a recipient animal (often into an irradiated or injured site). The ability of these cells to engraft, self-renew, and regenerate functional tissue is then assessed. For example, cross-depot transplantation of skin adipocyte progenitors has been used to demonstrate their distinct regenerative capacity compared to inguinal adipose progenitors [83].
Proliferation and Self-Renewal Assays: These assays measure a cluster's expansion potential. Techniques include tracking the incorporation of nucleoside analogues like EdU or BrdU into newly synthesized DNA, or performing serial colony-forming unit (CFU) assays, where cells are passaged repeatedly to assess long-term self-renewal capacity [82].
Visualizing the Validation Workflow
The following diagram illustrates the integrated workflow for computationally identifying stem cell subpopulations and subsequently validating them through biological methods.
Figure 1: Integrated workflow for computational clustering and biological validation of stem cell subpopulations.
The Scientist's Toolkit: Key Research Reagents
Successful biological validation relies on a specific toolkit of reagents and molecular tools. The following table details essential items for implementing the lineage tracing and functional assays described above.
Table 2: Key Research Reagents for Lineage Tracing and Functional Validation
| Reagent / Tool | Function in Validation | Key Considerations |
|---|---|---|
| Cre-loxP System | Permanent genetic labeling of lineages; inducible with CreERT2. | Requires cell-type-specific promoter for precise targeting [82]. |
| Fluorescent Reporters | Visualizing labeled lineages (e.g., GFP, RFP) or differentiation markers. | Multicolour systems (e.g., Confetti) enable clonal resolution [82] [81]. |
| Tamoxifen | Activates CreERT2 for temporal control of lineage tracing initiation. | Dose and timing are critical for sparse labeling [82]. |
| DNA Barcode Libraries | Introducing diverse, heritable DNA tags for high-resolution clonal tracking. | Delivered via retrovirus; suitable for proliferating cells [81]. |
| CRISPR/Cas9 System | Engineered to create mutable barcode loci that record cell division history. | Enables high-resolution lineage tree reconstruction [81]. |
| Cell Sorting Reagents | Isolation of specific cell clusters for functional assays (e.g., FACS). | Based on cluster-specific surface markers or reporter expression. |
| In Vivo Transplant Models | Testing regenerative potential of clusters (e.g., irradiated mice). | The gold standard for validating stem cell function in vivo [83]. |
This guide has provided a comparative overview of single-cell clustering algorithms and detailed the experimental protocols essential for their biological validation. The benchmark data indicates that while algorithms like scAIDE, scDCC, and FlowSOM generally demonstrate superior performance, the optimal choice is context-dependent and must balance accuracy, robustness, and computational resources [5].
The critical insight is that computational clustering generates hypotheses about cellular identity and relationship; these hypotheses must be tested through rigorous biological experimentation. Lineage tracing provides the definitive map of developmental history, while functional assays confirm the differential biological capacities of the identified groups. For instance, integrating single-cell RNA sequencing with lineage tracing has been pivotal in redefining the adipocyte progenitor hierarchy, revealing distinct differentiation potentials and identifying key regulators like Sox9 [83].
Therefore, a robust research pipeline in stem cell biology involves a continuous, iterative cycle: computational clustering informs the design of targeted lineage tracing and functional experiments, and the results from these biological validations, in turn, refine the computational models. This synergistic approach, powered by thoughtful experimental design [84], is fundamental to unraveling the true complexity of stem cell systems and advancing their therapeutic application.
Single-cell RNA sequencing (scRNA-seq) has revolutionized our ability to profile gene expression in individual cells, enabling researchers to dissect cellular heterogeneity within complex tissues and biological systems. This technology is particularly valuable for identifying and characterizing rare cell populations, including cancer stem cells (CSCs) and tracking differentiation pathways of pluripotent stem cells (PSCs). Clustering analysis serves as a fundamental computational step in scRNA-seq data analysis, grouping cells with similar transcriptomic profiles into biologically meaningful subpopulations. The choice of clustering algorithm significantly impacts downstream biological interpretations, making algorithm selection a critical decision in research design.
The performance of clustering algorithms varies considerably across different biological contexts and data types. As demonstrated by comprehensive benchmarking studies, methods optimized for one application may underperform in another due to differences in data distribution, feature dimensions, and underlying biological complexity. This comparison guide provides an objective evaluation of clustering algorithm performance through case studies in cancer stem cell and pluripotent stem cell research, offering evidence-based recommendations for researchers and drug development professionals.
Benchmarking Clustering Algorithms: Performance Metrics and Comparative Analysis
Key Performance Metrics for Clustering Evaluation
Researchers primarily use two complementary metrics to quantitatively evaluate clustering performance against known cell type labels: the Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI). ARI measures the similarity between the predicted clustering and ground truth labels, with values ranging from -1 to 1, where values closer to 1 indicate better performance. NMI quantifies the mutual information between clustering assignments and true labels, normalized to a 0-1 scale, where values closer to 1 represent superior alignment between clustering results and biological truth [5].
Additional practical considerations include computational efficiency (running time and peak memory usage) and robustness (consistency across different runs and dataset variations) [31] [26]. These factors become critically important when working with large-scale datasets containing tens of thousands of cells.
Comprehensive Algorithm Performance Comparison
Recent large-scale benchmarking studies have evaluated numerous clustering algorithms across diverse datasets. The following table summarizes the performance characteristics of top-performing methods based on comprehensive evaluations:
Table 1: Performance Comparison of Single-Cell Clustering Algorithms
| Algorithm | Overall Performance (ARI/NMI) | Computational Efficiency | Strengths and Specialized Applications | Modality Best Suited For |
|---|---|---|---|---|
| scAIDE | Top performer (Ranked 1st in proteomics, 2nd in transcriptomics) | Moderate | Excellent cross-modality performance, robust to noise | Transcriptomics & Proteomics |
| scDCC | Top performer (Ranked 1st in transcriptomics, 2nd in proteomics) | High memory efficiency | Superior for transcriptomic data, memory efficient | Primarily Transcriptomics |
| FlowSOM | Top performer (Ranked 3rd in both modalities) | High | Excellent robustness, handles large datasets well | Proteomics & Transcriptomics |
| Seurat | High quality (Ranked 4th in non-malignant cells) | Moderate | Effective for rare cell type detection | Transcriptomics |
| Monocle | Variable performance | Moderate | Superior for malignant cancer cells | Transcriptomics |
| SC3 | Variable performance | Moderate | Excellent for malignant cancer cells and rare cell types | Transcriptomics |
| TSCAN | Moderate performance | High time efficiency | Recommended for time-sensitive applications | Transcriptomics |
| SHARP | Moderate performance | High time efficiency | Suitable for large-scale data analysis | Transcriptomics |
| MarkovHC | Moderate performance | High time efficiency | Balanced performance across metrics | Transcriptomics |
A comprehensive 2025 benchmarking study evaluated 28 computational algorithms on 10 paired transcriptomic and proteomic datasets, revealing that scAIDE, scDCC, and FlowSOM consistently delivered top-tier performance across both omics modalities [31] [5]. These methods demonstrated strong generalization capabilities, effectively handling the distinct data distributions and feature dimensionalities characteristic of transcriptomic and proteomic data.
For cancer research specifically, a specialized evaluation of 15 clustering algorithms on eight cancer datasets revealed that algorithm performance differs significantly when clustering malignant versus non-malignant cells. While Seurat, bigSCale, and Cell Ranger achieved the highest clustering quality for non-malignant cells, Monocle and SC3 frequently outperformed other methods for malignant cells [85]. This distinction highlights the importance of selecting algorithms tailored to specific biological contexts.
Case Study 1: Identifying Cancer Stem Cell-Like Subpopulations in Hepatocellular Carcinoma
Experimental Design and Methodology
A 2024 study successfully identified a cancer stem cell-like subpopulation that promotes hepatocellular carcinoma (HCC) metastasis using single-cell RNA sequencing [76]. The research combined scRNA-seq with spatial transcriptomics to comprehensively map the tumor microenvironment and identify rare CSC populations driving metastasis.
The experimental workflow incorporated:
- Single-cell dissociation of hepatocellular carcinoma tissue samples
- Single-cell RNA sequencing using 10x Genomics platform
- Spatial transcriptomics to preserve spatial context within tumor tissue
- Integrated computational analysis to identify CSC subpopulations
For clustering analysis, the researchers employed a multi-algorithm approach to ensure robust identification of CSC subpopulations, leveraging the complementary strengths of different methods. This strategy helped mitigate limitations inherent in any single algorithm and provided greater confidence in the identified rare populations.
Key Findings and Algorithm Performance
The analysis successfully identified a distinct CSC-like subpopulation characterized by elevated expression of stemness markers and demonstrated this subpopulation's critical role in promoting HCC metastasis. The clustering algorithms effectively separated this rare population (comprising approximately 1-3% of total cells) from the bulk tumor cells, enabling subsequent functional characterization.
Algorithm benchmarking in similar cancer contexts has shown that Monocle and SC3 particularly excel at identifying malignant cell subpopulations, while Seurat demonstrates superior performance in detecting rare cell types [85]. These capabilities proved essential for the reliable identification of CSCs, which typically represent a small fraction of the total tumor cell population yet drive critical clinical phenotypes like metastasis and therapy resistance.
Figure 1: Experimental workflow for identifying cancer stem cell-like subpopulations in hepatocellular carcinoma using multi-omics approaches and clustering analysis.
Case Study 2: Mapping Pluripotent Stem Cell Differentiation Pathways
Experimental Design and Methodology
A 2025 study established a comprehensive pluripotent stem cell atlas of multilineage differentiation through detailed single-cell RNA sequencing [86]. The research aimed to understand gene expression changes governing differentiation in vitro, which is crucial for developing high-fidelity differentiation protocols and understanding fundamental mechanisms of development.
The experimental approach included:
- Mesendoderm-directed differentiation of human induced pluripotent stem cells (hiPSCs) over eight consecutive days
- Signaling pathway perturbations targeting WNT, BMP4, and VEGF pathways at germ layer stage
- Longitudinal scRNA-seq at multiple timepoints from pluripotency to committed cell types
- Multiplexed analysis using genetic barcoding to track differentiation outcomes
The dataset encompassed over 60,000 cells spanning a time course of differentiation across all germ layers, ranging from gastrulation cell states to progenitor and committed cell types. This comprehensive design enabled robust benchmarking of clustering algorithms in capturing distinct differentiation states and transitions.
Key Findings and Algorithm Performance
The study successfully mapped differentiation trajectories from pluripotency to various lineage-committed cell types, revealing novel insights into how signaling pathways influence cell fate decisions. The research demonstrated the utility of this integrated in vitro dataset for uncovering signaling-, temporal-, and lineage-specific regulators of differentiation.
For clustering such differentiation time courses, methods that effectively capture continuous transitions while maintaining discrete cell state identities are particularly valuable. The benchmarking analysis revealed that scDCC and scAIDE achieved superior performance in capturing the continuous nature of differentiation processes while still resolving distinct cell states [31] [5]. These methods leverage deep learning approaches that can model complex nonlinear relationships in the data, making them particularly suited for capturing differentiation trajectories.
Experimental Protocols for Reproducible Clustering Analysis
Standardized scRNA-seq Clustering Workflow
To ensure reproducible and robust clustering results, researchers should follow a standardized workflow:
Quality Control and Filtering
- Remove low-quality cells based on library size, number of detected genes, and mitochondrial percentage
- Filter out low-abundance genes detected in very few cells
- Use tools like Scater for systematic quality assessment [87]
Normalization and Feature Selection
- Apply appropriate normalization methods (e.g., log normalization in Seurat)
- Identify highly variable genes (HVGs) for downstream analysis
- Consider the impact of HVG selection on clustering performance [5]
Dimensionality Reduction
- Perform principal component analysis (PCA) on normalized data
- Use additional nonlinear methods (t-SNE, UMAP) for visualization
- Implement automatic dimension selection methods like scLENS [26]
Clustering Application
- Apply multiple clustering algorithms with appropriate parameters
- Assess clustering consistency using tools like scICE [26]
- Compare results across methods to identify robust clusters
Biological Validation and Interpretation
- Identify cluster-specific marker genes
- Annotate cell types based on known markers
- Validate clusters using functional enrichment analysis
Assessing Clustering Consistency with scICE
The single-cell Inconsistency Clustering Estimator (scICE) provides a framework for evaluating clustering consistency and reliability [26]. The method involves:
- Multiple clustering runs with different random seeds
- Element-centric similarity calculation between resulting labels
- Inconsistency coefficient computation to quantify reliability
- Identification of stable clustering resolutions for downstream analysis
scICE achieves up to 30-fold speed improvement compared to conventional consensus clustering methods while providing robust assessment of clustering stability, making it particularly valuable for large-scale datasets.
Figure 2: The scICE workflow for evaluating clustering consistency and identifying reliable cluster labels through multiple runs and inconsistency coefficient calculation.
Research Reagent Solutions for Stem Cell Studies
Table 2: Essential Research Reagents for Single-Cell Stem Cell Studies
| Reagent Category | Specific Product Examples | Application in Stem Cell Research |
|---|---|---|
| Stem Cell Culture Media | mTeSR1, StemMACS iPS-Brew XF | Maintenance of pluripotent stem cells in undifferentiated state |
| Extracellular Matrices | Matrigel, Vitronectin XF | Provision of substrate for pluripotent stem cell attachment and growth |
| Dissociation Reagents | Accutase, Accumax, EDTA solutions | Gentle dissociation of stem cell colonies into single cells |
| Signaling Modulators | CHIR99021 (WNT activator), BMP4, VEGF | Directed differentiation of pluripotent stem cells toward specific lineages |
| Cell Staining Reagents | Click-iT EdU Alexa Fluor kits, Hoechst 33342 | Cell cycle analysis and proliferation tracking |
| Antibody Panels | OCT4, NANOG, pHH3, SSEA-4 | Identification and validation of pluripotent and differentiated cell states |
| Cell Viability Assays | Trypan Blue, Propidium Iodide | Assessment of cell viability before single-cell RNA sequencing |
Based on comprehensive benchmarking studies and successful applications in stem cell research, we recommend:
For general-purpose clustering across transcriptomic and proteomic data: scAIDE, scDCC, and FlowSOM provide top-tier performance and excellent cross-modality generalization [31] [5].
For cancer stem cell identification: Monocle and SC3 excel particularly for malignant cell subpopulations, while Seurat demonstrates superior rare cell type detection capabilities [85].
For pluripotent stem cell differentiation studies: scDCC and scAIDE effectively capture continuous differentiation trajectories while maintaining discrete cell state resolution.
For large-scale studies prioritizing computational efficiency: TSCAN, SHARP, and MarkovHC offer excellent time efficiency, while scDCC and scDeepCluster provide memory-efficient solutions [31].
For ensuring clustering reliability: Implement scICE to evaluate clustering consistency and identify robust clustering resolutions, particularly important for large datasets and rare population identification [26].
The rapid advancement of single-cell technologies continues to drive method development, with emerging approaches increasingly focusing on multi-omics integration, trajectory inference, and handling of spatial transcriptomics data. Researchers should regularly consult updated benchmarking studies as new algorithms and methodologies continue to enhance our ability to unravel stem cell heterogeneity and fate decisions.
Conclusion
Effective clustering is fundamental to unlocking the complexity of stem cell systems, with significant implications for basic research and clinical translation. Benchmarking reveals that while no single algorithm excels in all scenarios, methods like scAIDE, scDCC, and FlowSOM consistently demonstrate robust performance across diverse stem cell datasets. The integration of multi-omics data and the development of automated parameter optimization tools are addressing key analytical challenges. Looking forward, the convergence of artificial intelligence, systems biology, and advanced clustering methodologies will enable more precise identification of stem cell subpopulations, accelerate drug discovery, and enhance the development of stem cell-based therapies. Researchers should adopt a context-aware approach to algorithm selection, considering their specific data modalities, computational constraints, and biological questions to maximize insights into stem cell biology and therapeutic potential.
References
- 1. Stem cell heterogeneity, plasticity, and regulation [https://www.sciencedirect.com/science/article/abs/pii/S0024320523008755]
- 2. Stem cell heterogeneity: implications for aging and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3355711/]
- 3. The heterogeneity of mesenchymal stem cells [https://pmc.ncbi.nlm.nih.gov/articles/PMC10734083/]
- 4. The issue of heterogeneity of MSC-based advanced ... [https://www.frontiersin.org/journals/cell-and-developmental-biology/articles/10.3389/fcell.2024.1400347/full]
- 5. Comparative benchmarking of single-cell clustering ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-025-03719-y]
- 6. Benchmarking clustering algorithms on estimating the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8822786/]
- 7. Pluripotent stem cell heterogeneity and the evolving role ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3311164/]
- 8. Cause and consequence of heterogeneity in human ... [https://www.sciencedirect.com/science/article/pii/S0344033824002656]
- 9. Frontiers | Optimization of clustering parameters for single- cell RNA... [https://www.frontiersin.org/journals/bioinformatics/articles/10.3389/fbinf.2025.1562410/full]
- 10. scMelody: An Enhanced Consensus-Based Clustering Model for... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8905497/]
- 11. Artificial Intelligence in Regenerative Medicine: Applications ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10526210/]
- 12. Single-cell Technology in Stem Cell Research [https://pubmed.ncbi.nlm.nih.gov/38243989/]
- 13. Advances in single-cell omics and multiomics for high- ... [https://www.nature.com/articles/s12276-024-01186-2]
- 14. Single-cell sequencing to multi-omics - Biomarker Research [https://biomarkerres.biomedcentral.com/articles/10.1186/s40364-024-00643-4]
- 15. Comparison of transformations for single-cell RNA-seq data [https://www.nature.com/articles/s41592-023-01814-1]
- 16. A Strategy to Compare Single-Cell RNA Sequencing Data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11457179/]
- 17. A systematic performance evaluation of clustering methods for single-cell RNA-seq data - PubMed [https://pubmed.ncbi.nlm.nih.gov/30271584/]
- 18. Benchmarking clustering algorithms on estimating the number of cell types from single-cell RNA-sequencing data | Genome Biology | Full Text [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-022-02622-0]
- 19. Tracking single hematopoietic stem cells in vivo using high ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3196379/]
- 20. Dissecting stem cell differentiation using single ... [https://www.sciencedirect.com/science/article/abs/pii/S0955067416301351]
- 21. Regulation of Stem Cell Plasticity - PubMed Central - NIH [https://pmc.ncbi.nlm.nih.gov/articles/PMC3345979/]
- 22. Engineering Lineage Potency and Plasticity of Stem Cells ... [https://www.nature.com/articles/s41598-018-34511-7]
- 23. Artificial intelligence and systems biology analysis in stem cell ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12476622/]
- 24. Comparative benchmarking of single-cell clustering ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12406447/]
- 25. A Comparative Study of Machine Learning Techniques for ... [https://www.mdpi.com/1999-4893/18/4/232]
- 26. scICE: enhancing clustering reliability and efficiency of ... [https://www.nature.com/articles/s41467-025-60702-8]
- 27. Deep learning-based predictive classification of functional ... [https://stemcellres.biomedcentral.com/articles/10.1186/s13287-024-03682-8]
- 28. Deep learning identifies heterogeneous subpopulations in ... [https://www.nature.com/articles/s44385-025-00023-z]
- 29. A systematic review of deep learning methods for community ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12411782/]
- 30. Simple yet effective heuristic community detection with ... [https://www.nature.com/articles/s41598-025-22860-z]
- 31. Comparative benchmarking of single-cell clustering ... [https://pubmed.ncbi.nlm.nih.gov/40903792/]
- 32. scAIDE: clustering of large-scale single-cell RNA-seq data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7671411/]
- 33. A comparison framework and guideline of clustering ... [https://pubmed.ncbi.nlm.nih.gov/31870419/]
- 34. A critical assessment of clustering algorithms to improve ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10782910/]
- 35. Subcellular Transcriptomics and Proteomics [https://pmc.ncbi.nlm.nih.gov/articles/PMC8864473/]
- 36. Comprehensive transcriptomic and proteomic ... [https://www.nature.com/articles/srep21507]
- 37. A transcriptomic and proteomic analysis and comparison of ... [https://www.nature.com/articles/s41598-025-00986-4]
- 38. Multitask benchmarking of single-cell multimodal omics ... [https://www.nature.com/articles/s41592-025-02856-3]
- 39. A progressive clustering method to identify cell populations [https://pmc.ncbi.nlm.nih.gov/articles/PMC10115987/]
- 40. Benchmarking multi-slice integration and downstream ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-025-03796-z]
- 41. A technical review of multi-omics data integration methods [https://pmc.ncbi.nlm.nih.gov/articles/PMC12315550/]
- 42. Benchmarking multi-omics integrative clustering methods ... [https://www.sciencedirect.com/science/article/abs/pii/S0169260725000203]
- 43. Evaluation and comparison of multi-omics data integration ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8384175/]
- 44. scCAD: Cluster decomposition-based anomaly detection ... [https://www.nature.com/articles/s41467-024-51891-9]
- 45. A survey of biclustering and clustering methods in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12342763/]
- 46. Comprehensive Guide to Cluster Analysis [https://www.displayr.com/understanding-cluster-analysis-a-comprehensive-guide/]
- 47. What is Feature Engineering? - Machine Learning [https://www.geeksforgeeks.org/machine-learning/what-is-feature-engineering/]
- 48. What is a feature engineering? | IBM [https://www.ibm.com/think/topics/feature-engineering]
- 49. What is Feature Extraction? Feature Extraction Techniques ... [https://domino.ai/data-science-dictionary/feature-extraction]
- 50. A Comprehensive Guide to Dimensionality Reduction [https://medium.com/@adnan.mazraeh1993/a-comprehensive-guide-to-dimensionality-reduction-from-basic-to-super-advanced-techniques-9-3e3f3eeb8814]
- 51. Elbow Method for Optimal Cluster Number in K-Means [https://www.analyticsvidhya.com/blog/2021/01/in-depth-intuition-of-k-means-clustering-algorithm-in-machine-learning/]
- 52. Elbow Method Alternatives to find Number of Clusters [https://www.nb-data.com/p/elbow-method-alternatives-to-find]
- 53. Better than Elbow Method to find Optimal Clusters [https://medium.com/data-science/silhouette-method-better-than-elbow-method-to-find-optimal-clusters-378d62ff6891]
- 54. Reference Vector-guided Evolutionary Algorithm for cluster ... [https://www.sciencedirect.com/science/article/pii/S0169260725002901]
- 55. Pre-Determining the Optimal Number of Clusters for k- ... [https://www.mdpi.com/2076-3417/15/21/11372]
- 56. scEVE: a single-cell RNA-seq ensemble clustering ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12147100/]
- 57. Comparison of the effectiveness of different normalization ... [https://www.nature.com/articles/s41598-024-57670-2]
- 58. Batch to the Future: How normalisation tools help reduce ... [https://help.omiq.ai/hc/en-us/articles/40037326944148-Batch-to-the-Future-How-normalisation-tools-help-reduce-batch-effect-in-high-parameter-cytometry]
- 59. Highly effective batch effect correction method for RNA-seq ... [https://www.sciencedirect.com/science/article/pii/S200103702400432X]
- 60. A comparison of automatic cell identification methods for ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-019-1795-z]
- 61. Identification of cell subpopulations associated with disease ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10354926/]
- 62. A single cell RNAseq benchmark experiment embedding “ ... [https://www.nature.com/articles/s41597-024-03002-y]
- 63. scSID: A lightweight algorithm for identifying rare cell types ... [https://www.sciencedirect.com/science/article/pii/S2001037023005184]
- 64. Feature selection methods affect the performance of ... [https://www.nature.com/articles/s41592-025-02624-3]
- 65. Optimizing high dimensional data classification with a ... [https://www.nature.com/articles/s41598-025-08699-4]
- 66. An Analytical Benchmark of Feature Selection Techniques ... [https://www.mdpi.com/2076-3417/15/3/1457]
- 67. Comprehensive review of dimensionality reduction ... [https://peerj.com/articles/cs-3025/]
- 68. Benchmarking of dimensionality reduction methods to ... [https://www.nature.com/articles/s41598-025-12021-7]
- 69. Benchmarking Dimensionality Reduction Techniques for ... [https://arxiv.org/abs/2509.13344]
- 70. Benchmarking multi-slice integration and downstream ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12477787/]
- 71. A Comparative Study of Sequence Clustering Algorithms [https://www.sciopen.com/article/10.26599/BDMA.2025.9020010?issn=2096-0654]
- 72. K-Volume Clustering Algorithms for scRNA-Seq Data ... [https://www.mdpi.com/2079-7737/14/3/283]
- 73. Artificial variables help to avoid over-clustering in single- ... [https://www.sciencedirect.com/science/article/pii/S0002929725000618]
- 74. Optimizing clustering-based analytical methods with ... [https://www.sciencedirect.com/science/article/pii/S0010482525007875]
- 75. Unsupervised multiscale clustering of single-cell ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12509883/]
- 76. Identification of a cancer stem cell-like subpopulation that ... [https://www.sciencedirect.com/science/article/pii/S2589555924003069]
- 77. Stem Cell Therapy Market Analysis & Forecast: 2025-2032 [https://www.coherentmarketinsights.com/market-insight/stem-cell-therapy-market-2848]
- 78. Stem Cell Therapy Market Skyrockets at 25.26% CAGR ... [https://www.towardshealthcare.com/insights/stem-cell-therapy-market-sizing]
- 79. Cell Granularity Reflects Immune Cell Function and Enables ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10558660/]
- 80. Consensus prediction of cell type labels in single-cell data ... [https://www.nature.com/articles/s41588-024-01993-3]
- 81. Single-cell lineage tracing techniques in hematology [https://pmc.ncbi.nlm.nih.gov/articles/PMC11877926/]
- 82. Next generation lineage tracing and its applications ... [https://www.nature.com/articles/s41540-025-00542-w]
- 83. Comparative single-cell lineage tracing identifies distinct ... [https://www.sciencedirect.com/science/article/pii/S1934590925002619]
- 84. How thoughtful experimental design can empower ... [https://www.nature.com/articles/s41467-025-62616-x]
- 85. Evaluation of single-cell RNA-seq clustering algorithms on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9677128/]
- 86. A pluripotent stem cell atlas of multilineage differentiation [https://www.nature.com/articles/s41597-025-05549-w]
- 87. Single-cell RNA-seq clustering: datasets, models, and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7549635/]